

Redis를 사용할 때 물리 머신이 가진 메모리의 한계를 초과하는 데이터를 저장하고 싶거나, failover에 대한 처리를 통해 HA를 보장하려면 Sentinal이나 Cluster 등의 운영 방식을 선택해서 사용해야한다.
Sentinel
기능
- 모니터링: Master/Slave가 제대로 동작하는지 지속적으로 감시한다.
- 자동 장애 조치
- 알림: failover되었을 때 pub/sub로 client에게 알리거나, shell script로 이메일이나 sms를 보낼 수 있다.
동작 방식
Sentinal 인스턴스 과반 수 이상이 Master 장애를 감지하면 Slave중 하나를 Master로 승격시키고 기존의 Master는 Slave로 강등시킨다.
Slave가 여러개 있을 경우 Slave가 새로운 Master로부터 데이터를 받을 수 있도록 재구성된다.
과반 수 이상으로 결정하는 이유는 만약 어느 Sentinel이 단순히 네트워크 문제로 Master와 연결되지 않을 수 있는데, 그 때 실제로 Master는 다운되지 않았으나 연결이 끊긴 Sentinel은 Master가 다운되었다고 판단할 수 있기 때문이다.
failover 감지 방법
- SDOWN: Subjectively down(주관적 다운)
- Sentinel에서 주기적으로 Master에게 보내는 Ping과 Info 명령의 응답이 3초(down-after-milliseconds에서 설정한 값) 동안 오지 않으면 주관적 다운으로 인지한다.
- 센티널 한 대에서 판단한 것으로, 주관적 다운만으로는 장애조치를 진행하지 않는다.
- ODOWN: Objectively down(객관적 다운)
- 설정한 quorum 이상의 센티널에서 해당 Master가 다운되었다고 인지하면 객관적 다운으로 인정하고 장애 조치를 진행한다.
failover시 주의사항
get-master-addr-by-name: Master,Slave 모두 다운되었을 때 센티널에 접속해 Master 서버 정보를 요청하면 다운된 서버 정보를 리턴한다. 따라서 Info sentinel 명령으로 마스터의 ststus를 확인해야한다.
Slave -> Master 승격 안되는 경우: Slave 다운 -> Master 다운 -> 다운된 Slave 재시작시 이 서버는 Master로 전환되지 않는다. Slave의 redis.conf에 자신이 복제로 되어있고, 센티널도 복제라고 인식하고 있기 때문이다. 해결책은 Slave가 시작하기 전에 redis.conf에서 slaveof로 삭제하는 것이다.
기타
- Quorom: Redis 장애 발생시 몇 개의 센티널이 특정 Redis의 장애 발생을 감지해야 장애라고 판별하는지를 결정하는 기준 값. 보통 reids의 과반수 이상으로 설정한다.
- 센티널은 1차 복제만 Master 후보에 오를 수 있다. (복재 서버의 복제 서버는 불가능)
- 1차 복제 서버 중 replica-priority 값이 가장 작은 서버가 마스터에 선정된다. 0으로 설정하면 master로 승격 불가능하고 동일한 값이 있을 때에는 엔진에서 선택한다.
- 안정적 운영을 위해 3개 이상의 센티널을 만드는 것을 권장하는데, 서로 물리적으로 영향받지 않는 컴퓨터나 가상 머신에 설치되는 것이 좋다.
- 센티널은 내부적으로 redis의 Pub/Sub 기능을 사용해서 서로 정보를 주고받는다.
- 센티널 + 레디스 구조의 분산 시스템은 레디스가 비동기 복제를 사용하기때문에, 장애가 발생하는 동안 썼던 내용들이 유지됨을 보장할 수 없다.
- Sentinel을 Redis와 동일한 Node에 구성해도 되고, 별도로 구성해도 된다
- 클라이언트는 주어진 서비스를 담당하는 현재 레디스 마스터의 주소를 요청하기 위해 센티널에 연결한다. 장애 조치가 발생하면 센티널은 새 주소를 알려준다
Cluster
기능
- 자동 장애 조치
- 샤딩: 데이터를 분산 저장
동작 방식
- 해시 슬롯을 이용해 데이터를 샤딩한다.
- 샤딩: 데이터를 분산 저장하는 방식
- 해시 슬롯: CRC-16 해시 함수를 이용해 key를 정수로 변환하고, 해당 정수값을 16,385로 모듈 연산한 값
- 클러스터는 총 16384개의 해시 슬롯이 있으며 각 마스터 노트에 자유롭게 할당 가능 ex) 마스터 노드가 3개일 경우 1번 노드는 0~5460, 2번 노드는 5461~10922, 3번 노드는 10923~16383의 슬롯 할당
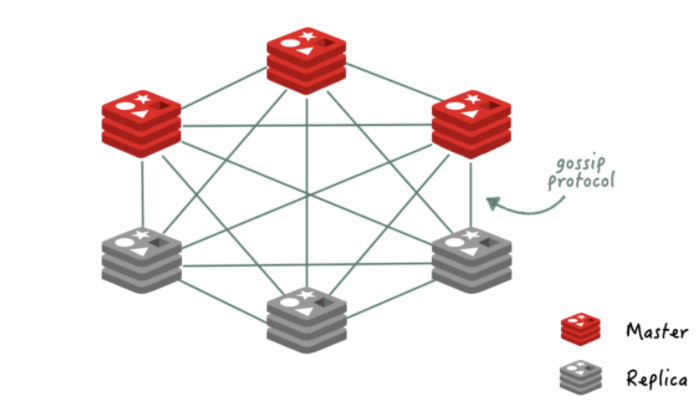
- Master가 죽을 경우 Master의 Slave는 gossip protocol을 통해 Master의 죽음 파악, Slave중 하나가 Master로 승격 -> 무중단 서비스 제공
- gossip protocol: 각 Redis는 다른 Redis들과 직접 연결하여 상태 정보를 통신한다.
- 기존 Master가 다시 살아나면 새로운 Master의 Slave가 된다.
기타
- 센티널보다 더 발전된 형태이다.
- Multi-Master, Multi-Slave 구조
- 1000대의 노드까지 확장 가능
- 모든 데이터는 Master 단위로 샤딩, Slave 단위로 복제
- Master마다 최소 하나의 Slave 권장, Slave가 하나도 없을 경우 Master 노드가 작동이 안되면 데이터 유실 가능성 존재
- 노트를 추가/삭제할 때 운영 중단 없이 해시 슬롯 재구성 가능
- failover 발생시 Slave가 Master로 승격할 때까지 문제가 발생한 마스터로 할당된 슬롯의 키는 사용 불가
- 키 이동시 해당 키에 잠시 락이 걸릴 수 있다.
- 과반수 이상의 노드 다운시 cluster가 깨진다.
- Replication은 Async 방식으로 이루어지기 떄문에 데이터 정합성이 깨질수 있다. 이는 나중에 Master가 된 데이터를 기준으로 정합성을 맞춘다.
- Cluster Redis는 2개의 포트가 필요하다. (클라이언트용 포트, 노드간 통신 포트)
- gossip protocol은 Redis Client가 이용하는 포트 번호보다 10000 높은 포트 번호 이용
- 클라이언트가 Redis에 데이터를 요청했을 때, 올바르지 않은 Master node에 요청하면 해당 데이터가 저장된 위치를 Client에 알려주고 Client는 제대로 된 주소에 다시 요청한다.
결론
Cluster를 사용하는 것이 좋다.
센티널은 One Master 구조이기 때문에 사이즈가 커지면 스케일 업을 해야하는데, Cluster는 스케일 아웃이 가능하기 때문 -> 확장성이 좋다.