
AS-IS
OPEN AI 서비스를 사용하는 이력서 검토 서비스는 외부 API에 의존하고 있었습니다.
때문에 요청부터 응답까지 적게는 30초부터, 길게는 1분 30초 정도까지 소요되는 사용성을 저하시키는 이슈가 있었습니다.
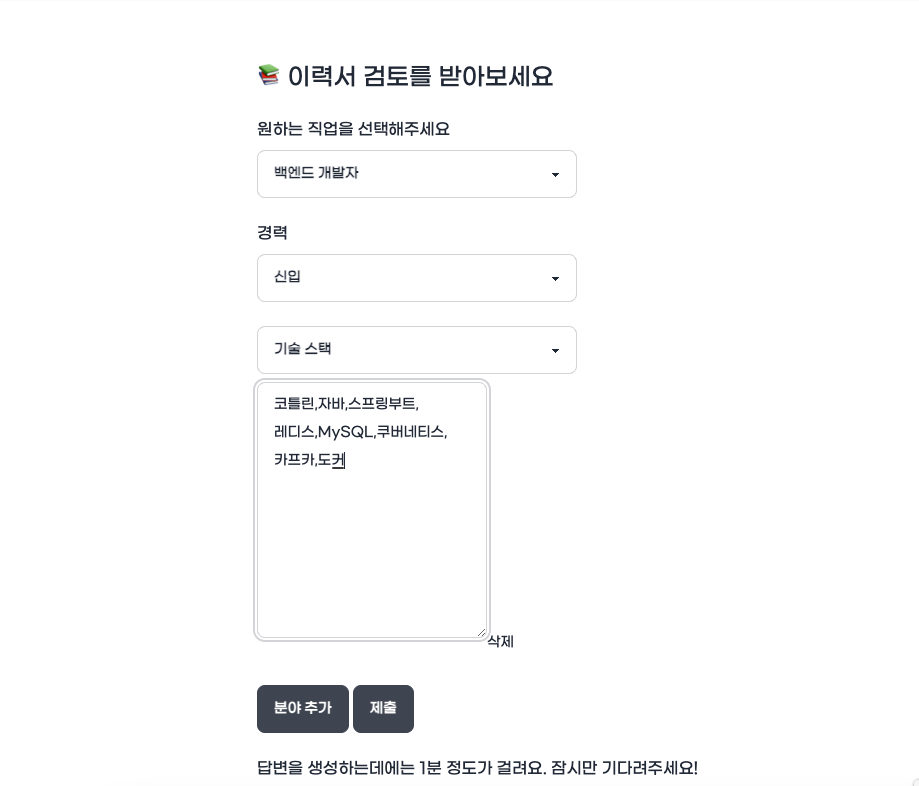
위 폼에서 제출을 누르면, 사용자는 하염없이 기다리게됩니다.
실수로 새로고침을 누르거나 다른 페이지로 이동할 경우 폼이 초기화되기도 합니다.
이러한 점에 대해서 로딩 창을 추가하는 것과 추가로 다른 기능을 개발하는 것을 고민했는데,
로딩창을 추가해도 기다리는 것은 똑같으니, 아예 다른 방향으로 기능을 확장하는 방향으로 노선을 정했습니다.
서비스 요청을 하면 카프카 토픽으로 메시지를 보내고, 서비스 로직에서 컨슘하여 외부 API를 호출하고 응답을 받아 DB에 저장하게 되는 기능을 생각했습니다.
이렇게 되면 사용자는 다른 서비스를 사용하다가도 요청이 처리되면 마이 페이지에서 요청 받은 내용을 확인할 수 있게 됩니다.
처음에는 @Async 어노테이션으로도 비동기 처리를 쉽게 할 수 있지 않을까 라는 생각도 해보았지만,
현재 서비스 현재는 멀티 모듈 싱글 프로젝트이지만, 추후 멀티 모듈 멀티 프로젝트로 확장을 해보고 싶은 마음이 있었습니다.
또한 배포 환경이 도커에서 쿠버네티스로 이전함에 따라, 프로젝트를 여러개 띄우더라도 사양에 문제가 없는 환경이 되어 최종적으로는 카프카를 중심으로한 이벤트 드리븐 아키텍처를 구현해보고싶었습니다.
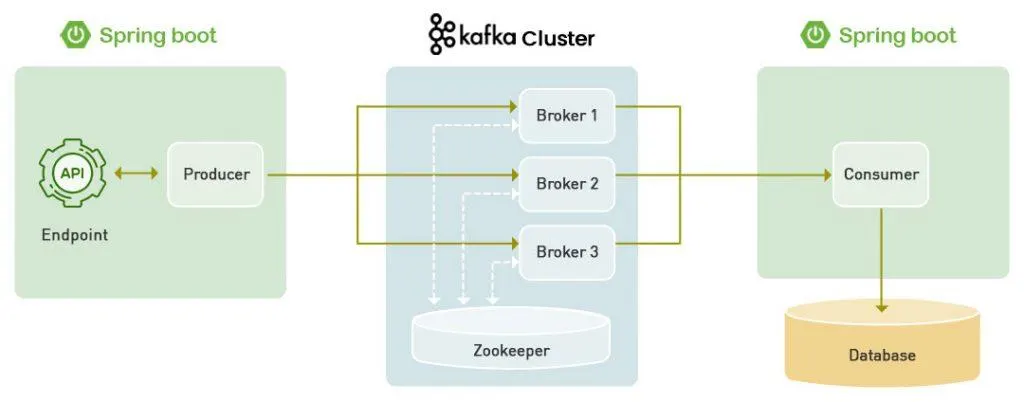
카프카 사용하기
KafkaConfig를 통해 컨슈머 팩토리와 프로듀서 팩토리를 Map으로 설정하여 빈으로 등록하는 방법도 있지만,
스프링 카프카에서는 yaml파일에 정의하는 것 만으로도 손쉽게 사용할 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: gptgroup
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
저는 application.yml에 위와 같이 컨슈머와 프로듀서의 직렬화, 역직렬화 정보를 포함해서 정의했고,
이제 손쉽게 KafkaProducerAdaptor를 정의해서 사용했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
@Service
@RequiredArgsConstructor
public class KafkaProducerAdaptor {
private static final String TOPIC_QUESTION = "question-request";
private static final String TOPIC_ADVICE = "advice-request";
private final KafkaTemplate<String, String> kafkaTemplate;
public void sendQuestionRequest(String message) {
this.kafkaTemplate.send(TOPIC_QUESTION, message);
}
public void sendAdviceRequest(String message) {
this.kafkaTemplate.send(TOPIC_ADVICE, message);
}
}
저희는 현재 멀티 모듈 싱글 프로젝트이기에 api-core-batch 모듈로 나누어져 있는데요.
api 모듈에 있는 Controller단에서 요청을 받아 처리하게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
@Controller
@RequiredArgsConstructor
@Slf4j
@RequestMapping("/resumes")
public class ResumeController {
private final Rq rq;
private final KafkaProducerAdaptor kafkaProducerAdaptor;
private final ObjectMapper objectMapper;
//...다른 로직
@GetMapping("/advices")
public String showAdviceForm() {
return "resume/advice-request";
}
@PostMapping("/advices")
public String generateAdvice(@ModelAttribute CreatePromptRequest request) throws JsonProcessingException {
if (rq.getMember() == null) {
request.setMemberId(null);
//...다른 로직
} else {
request.setMemberId(rq.getMember().getId());
kafkaProducerAdaptor.sendAdviceRequest(objectMapper.writeValueAsString(request));
}
return "resume/request-complete";
}
//...다른 로직
}
CreatePromptRequest 객체를 String 타입으로 역직렬화를 한 뒤, 카프카 큐에 메시지를 보내게 됩니다.
그리고 이제 core 모듈의 송신한 메시지의 토픽을 구독중인 비즈니스 로직에서 이를 받아 처리하게됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@KafkaListener(topics = "answer-request", groupId = "gptgroup")
public void generateAdviceWithKafka(String message) {
try {
CreatePromptRequest request = objectMapper.readValue(message, CreatePromptRequest.class);
log.info("이력서 생성 update request: {}",request.toString());
// memberId가 null이 아닌 경우에만 실행
if (request.getMemberId() != null) {
List<ResumeRequest> resumeData = request.getResumeRequests();
WhatGeneratedImproveResponse response = gptService.createdImprovementPointsAndAdvice(request.getJob(), request.getCareer(), resumeData);
savePredictionUseCase.savePrediction(response.toServiceDto(request.getMemberId()));
} else {
log.debug("비 로그인 유저이므로 데이터가 남지 않습니다.");
}
} catch (Exception e) {
throw new BusinessException(ErrorCode.CREATE_PREDICTION_QUESTION);
}
}
만약 직렬화, 역직렬화 설정을 저처럼 StringSerializer가 아닌 JsonSerializer를 사용할 경우 객체 자체를 넘길수도 있다고 합니다.
수신이 정상적으로 되었는지 확인하기 위해 로그를 찍어놓았기 때문에 CloudWatch로 들어가 확인해보면,

정상적으로 컨슘을 했다는 것을 확인할 수 있습니다.
그리고 DB에는 다음과 같이 저장되는 것을 확인할 수 있습니다.

TO-BE
이제 사용자는 제출을 누르면 제출이 완료되었다는 페이지를 받고,
다른 서비스를 사용할 수 있습니다.
그리고 다른 서비스를 이용 중, 답변이 생성되었다는 알림을 받으면 마이페이지에서 확인할 수 있게 되었습니다.
카프카를 현재는 단순 요청과 응답을 비동기로 처리하기위해 사용했지만,추후 더 많은 점을 개선할 수 있을 것 같습니다.
생성 AI 서비스 자체를 프로젝트로 만들어 영속성 프로젝트와 완전히 분리해서 카프카를 이용한 이벤트 드리븐 아키텍처로 전환할 수도 있으며,
api 모듈과 core 모듈이 완전히 분리되어 변경과 확장에서 자유로워졌습니다.
이러한 점이 MicroSevice Architecture로의 전환의 장점이라는 생각이 들었습니다.