
카프카의 컨트롤러로 주키퍼를 사용하고 멀티 브로커로 카프카를 실행하던 중, Kraft 모드에 대해 알게된 점을 공유하는 글입니다.
카프카 클러스터를 구성할 때에는 클러스터 환경 관리를 위한 코디네이터 애플리케이션이 필요합니다.
그래서 보통 아파치 주키퍼가 많이 사용되고 있습니다.
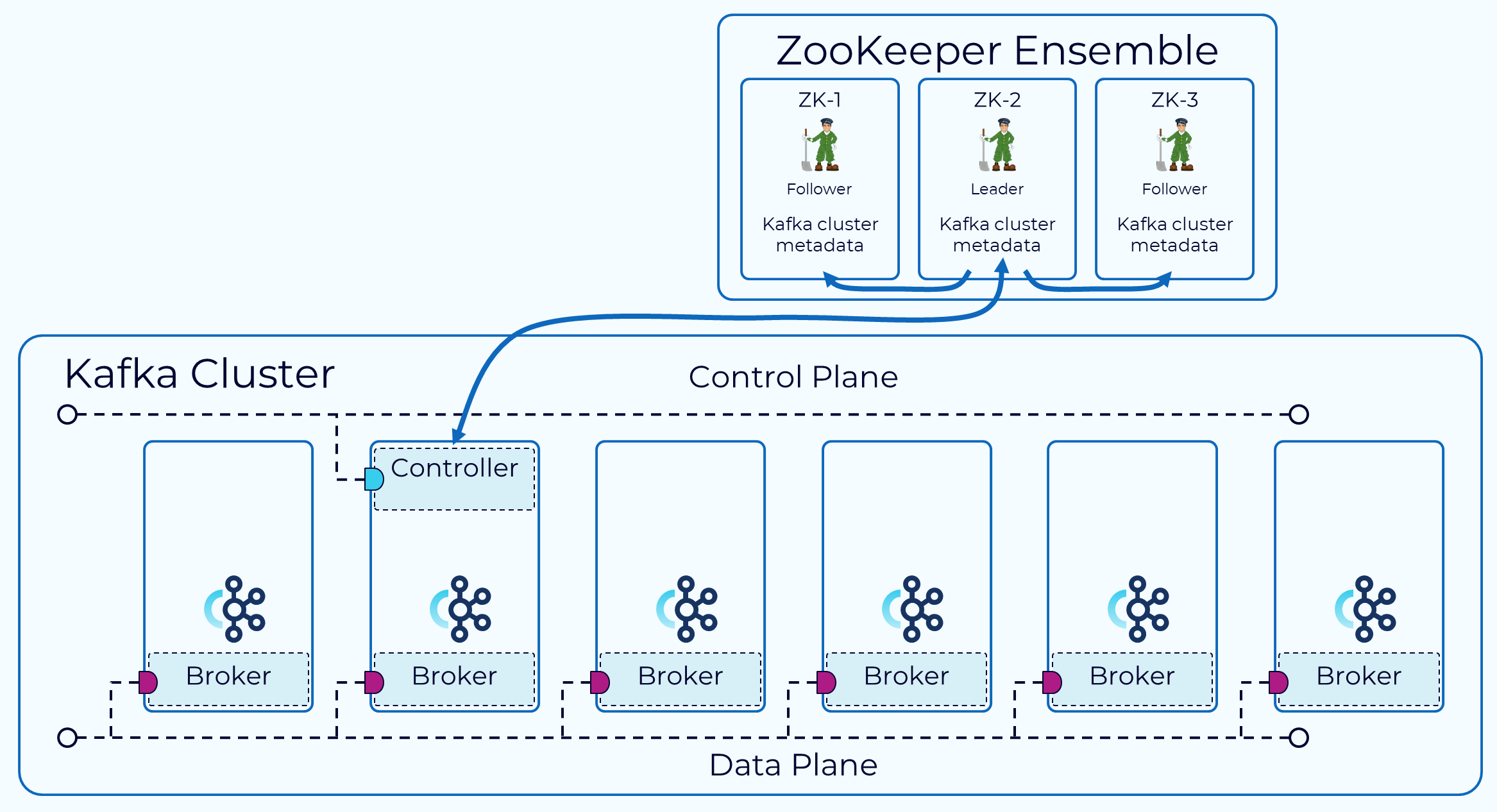
다만 주키퍼를 통한 카프카 외부에서 메타데이터 관리를 하다보니 데이터의 중복, 브로커와 컨트롤러(주키퍼)사이의 메타데이터 정합성 문제, 시스템 복잡성 증가, 주키퍼와 카프카를 같이 실행함에 따라 자바 프로세스의 증가와 같은 더 많은 자원 소모의 문제점들이 있습니다.
카프카 자체가 아닌 외부에서 메타 데이터를 관리하기 때문에, 카프카를 사용함으로써 확장성과 사용시 제약사항에 한계성을 느끼게 되며, 결과적으로는 카프카의 확장성에 제한이 됩니다.
그래서 새로이 메타데이터 관리를 카프카 자체에서 하기 위해 만들어진 것이 KRaft모드입니다.
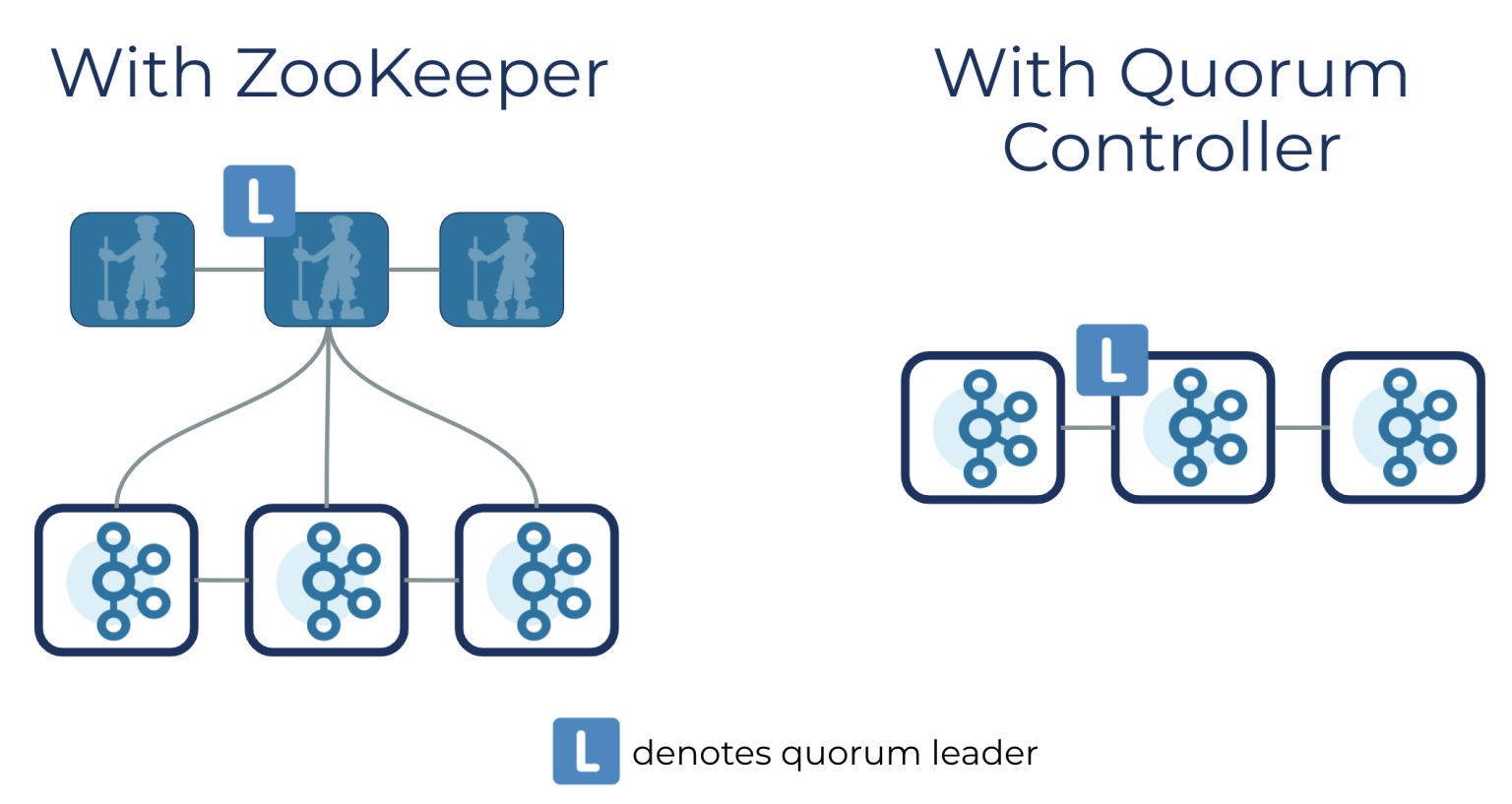
KRaft모드는 이전 컨트롤러를 대체하고, KRaft 합의 프로토콜 이벤트 기반 변형을 사용하는 Kafka의 새로운 쿼럼 컨트롤러 서비스를 사용합니다.
KRaft모드란?
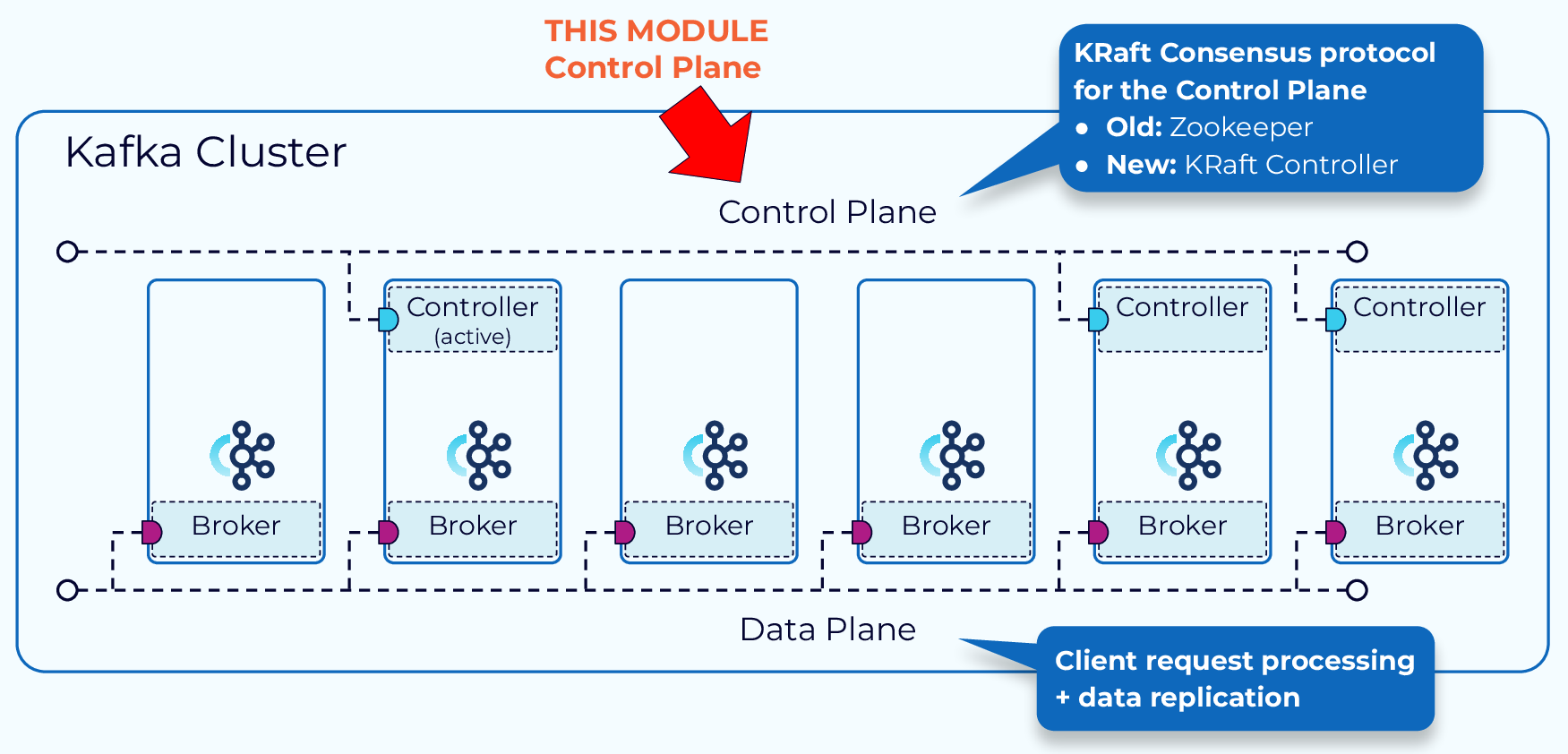
KIP-500에 따르면, 카프카에서 주키퍼에 대한 의존성을 제거하고 있습니다.
그래서 카프카 2.8 버전 이상부터는 주키퍼 없이 카프카를 실행시킬 수 있는 KRaft 모드(Kafka Raft metadata mode)가 등장하게 되었습니다.
그리고,크래프트 모드를 사용하는 것에 대한 이점으로, 컨플루엔트 사이트에서는 아래와 같은 것을 내세우고 있습니다.
- 새로운 메타데이터 관리로 제어 플레인 성능을 개선하여 Kafka 클러스터를 수백만 개의 파티션으로 확장할 수 있습니다.
- 안정성을 개선하고 소프트웨어를 간소화하며 Kafka를 더 쉽게 모니터링, 관리 및 지원할 수 있습니다.
- Kafka가 전체 시스템에 대해 단일 보안 모델을 갖도록 지원
- Kafka를 시작할 수 있는 가벼운 단일 프로세스 방법 제공
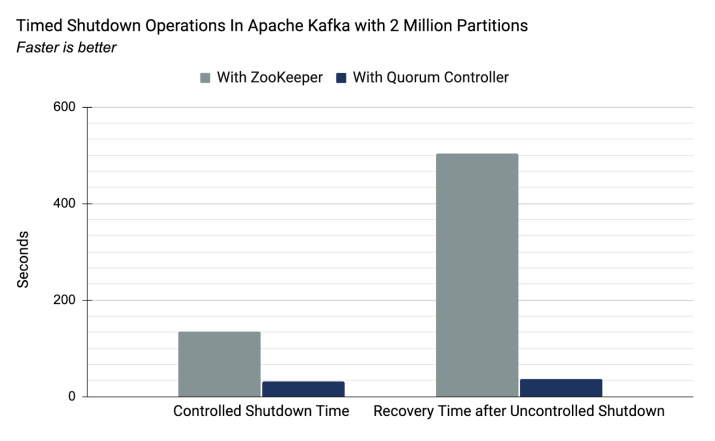
- 컨트롤러 페일오버를 거의 즉각적으로 수행
그리고 실제로, 리커버리 타임에 대해 주키퍼를 사용할 때보다 월등한 속도를 보여줍니다.
카프카를 실제로 설치해보면, sh파일이 모여있는 config 폴더에 kraft라는 폴더에 새로운 설정 파일이 추가되어 있음을 확인할 수 있습니다.
주키퍼 모드에 비해 추가되거나 삭제된 것은 아래와 같습니다.
제거된 설정
- zookeeper.connect
- zookeeper.*
- broker.id
- node.id로 대체됨
추가된 설정
- process.roles
- 해당 서버의 역할을 설정한다.
- node.id(broker.id 대체)
- controller.quorum.voters
- 기존 zookeeper quorum을 대체하는 controller quorum. 1대 이상 필요, 3대 or 5대 권장
작동 원리
쿼럼 컨트롤러는 Kraft 프로토콜을 사용해서 메타데이터가 쿼럼 전체에 복제되도록 해줍니다.
쿼럼 컨트롤러는 이벤트 기반 저장소 모델을 사용하여 상태를 저장하며, 이를 통해 내부 상태 시스템을 항상 정확하게 다시 만들 수 있습니다.
쿼럼 내의 다른 컨트롤러는 활성 컨트롤러가 만들고 로그에 저장하는 이벤트에 응답하여 활성 컨트롤러를 따릅니다. 따라서 예를 들어 파티셔닝 이벤트로 인해 한 노드가 일시 중지된 경우 다시 조인할 때 로그에 액세스하여 놓친 이벤트를 빠르게 따라잡을 수 있습니다.
얼리 액세스
카프카 2.8버전 부터 사용할 수 있는 Kraft 모드는 3.2버전까지는 개발 단계이므로 실 운영시에 사용하는 것을 권장하지 않습니다.
설치
저는 우선 리눅스 CentOS 7.8 버전을 사용하였고, 자바 17 버전을 설치해놓았습니다.
우선 카프카를 다운받아줍니다.
1
2
3
wget https://downloads.apache.org/kafka/3.4.1/kafka_2.13-3.5.0.tgz
tar xvf kafka_2.13-3.5.0.tgz -C /usr/local
압축을 풀 위치로 저는 /usr/local 폴더 내로 했습니다.
그리고 편의성을 위해 심볼릭 링크를 생성해줍니다.
1
2
3
cd /usr/local
ln -s. kafka_2.13-3.5.0 kafka
그리고 카프카 폴더로 가보면, config 폴더 내에 kraft 폴더가 존재함을 알 수 있습니다.
이제 카프카를 실행시키기 위해 server.properties를 바꿔주어야합니다.
kraft 폴더의 server.properties를 사용하면 됩니다.
그 중, 아래와 같은 점을 고치면 됩니다.
1
2
3
4
5
6
7
process.roles=broker,controller
node.id=0
controller.quorum.voters=0@172.17.20.57:9093,1@172.17.20.58:9093,2@172.17.20.59:9093
listeners=PLAINTEXT://:9092,CONTROLLER://:9093
advertised.listeners=PLAINTEXT://172.17.20.57:9092
controller.listener.names=CONTROLLER
log.dirs=/tmp/kraft-combined-logs
특히, 이제 카프카 서버가 브로커의 역할을 함과 동시에 컨트롤러 역할도 할 수 있기 때문에 process.roles를 설정하는 것은 필수입니다.
카프카 공식 리드미에서는 아래와 같이 예시를 들어 설명하고 있습니다.
So if you have 10 brokers and 3 controllers named controller1, controller2, controller3, you might have the following configuration on controller1:
1
2
3
4
process.roles=controller
node.id=1
listeners=CONTROLLER://controller1.example.com:9093
controller.quorum.voters=1@controller1.example.com:9093,2@controller2.example.com:9093,3@controller3.example.com:9093
저는 위 설정에서 log.dirs에 대해서는 kafka 폴더와 같은 위치에 생성하려고
1
2
3
log.dirs=/usr/local/kafka/kraft-combined-logs
mkdir -p /usr/local/kafka/kraft-combined-logs
로 변경해주었습니다.
이제 서버를 실행하기 전에 format 명령을 해주어야하는데,
클러스터 ID를 UUID를 직접 생성해야합니다.
공식 리드미에 따르면 자동으로 생성되던 클러스터 ID 방식이 떄떄로는 오류를 모호하게 만들었다고 합니다.
새 클러스터 ID는 kafka-storage.sh를 사용해서 생성해줍니다.
1
2
$ ./bin/kafka-storage.sh random-uuid
xtzWWN4bTjitpL3kfd9s5g
이제 생성된 uuid를 복사하고, logs 폴더를 포맷해줍니다.
1
2
$ ./bin/kafka-storage.sh format -t <uuid> -c ./config/kraft/server.properties
Formatting /tmp/kraft-combined-logs
위와 같이 Formatting 메시지가 나오면 성공입니다.
이제 실행해봅시다.
1
2
3
4
$ ./bin/kafka-server-start.sh ./config/kraft/server.properties # 실행
$ ./bin/kafka-server-start.sh -daemon config/kraft/server.properties # 백그라운드 실행
...
성공적으로 포트가 오픈되었는지 확인해보면
1
2
3
4
5
6
7
sudo netstat -antp | grep 9092
tcp6 0 0 :::9092 :::* LISTEN 17397/java
sudo netstat -antp | grep 9093
tcp6 0 0 :::9093 :::* LISTEN 17397/java
tcp6 0 0 10.178.0.2:9093 34.22.95.181:55582 ESTABLISHED 17397/java
tcp6 0 0 10.178.0.2:55582 34.22.95.181:9093 ESTABLISHED 17397/java
위와 같이 나오면 성공입니다.
멀티 브로커
다음으로는 멀티 브로커를 KRaft 모드로 실행시키는 방법에 대해서 공유하려고 합니다.
KRaft 모드가 정식으로 출시한지 얼마 되지 않아 정보가 너무 없어 파편화된 정보를 끌어모아 적용하게 되었습니다.
우선, 위 첫번째 브로커를 생성할 때의 server.properties를 카피했습니다.
저는 두번째 서버도 브로커와 컨트롤러의 역할을 하는 서버로 실행시킬 것이기 때문에 다음과 같이 적용했습니다.
1
2
3
4
5
6
7
process.roles=broker,controller
node.id=1
controller.quorum.voters=0@외부IP:9093,1@외부IP:9095
listeners=PLAINTEXT://:9094,CONTROLLER://:9095
advertised.listeners=PLAINTEXT://외부IP:9094
controller.listener.names=CONTROLLER
log.dirs=/usr/local/kakfa/kraft-combined-logs2
클라이언트에게 노출할 포트는 9094포트이고 컨트롤러 포트는 9095 포트로 설정했습니다.
만약, 브로커마다 서버를 다르게 쓴다면, 컨트롤러 둘 다 9093 포트에 외부 IP만 다르게 해도 됩니다.
그리고, log.dirs는 기존의 kraft-combined-logs2를 생성해서 바인딩해줍니다.
server.properties
상기 실행했던 첫번째 서버에서도 두번째 서버의 컨트롤러 주소를 추가해주어야합니다.
1
controller.quorum.voters=0@외부IP:9093,1@외부IP:9095
server.properties의 위 voters에 두번째 서버(노드 번호 1)도 추가해줍니다.
이제 설정은 끝났고 실행시키기만 하면 됩니다.
트러블 슈팅
에러 로그 없이 종료되는 경우
간혹, 에러가 발생하지 않는데도 종료되는 이슈가 발생합니다.
저도 처음에는 JVM 힙 이슈인 줄 알고 힙 설정을 따로 해주었지만, 마찬가지 증상이 지속되었고,
카프카는 자바를 사용하기 때문에 top 명령어로 자바 프로세스의 사용량을 확인해볼 수 있는데
top 명령어로 확인해보니 두번째 서버를 실행시킬 때 CPU 사용량이 100%를 넘어서 강제 종료가 되는 이슈가 있었습니다.
IllegaStateException이 발생할 때
server.properties에서 서버 2의 컨트롤러 주소를 입력하고 나서 서버 1을 재실행 했을때 발생한 이슈입니다.
에러 로그는 다음과 같았습니다.
1
java.lang.IllegalStateException: Configured voter set: [0, 1] is different from the voter set read from the state file: [0]. Check if the quorum configuration is up to date, or wipe out the local state file if necessary
이 에러 메시지는 Kafka 서버의 설정과 상태 파일 사이에 불일치가 있음을 나타냅니다.
특히, 설정된 voter set은 [1, 2]이지만, 상태 파일에서 읽은 voter set은 [1]입니다. 이로 인해 Kafka 서버가 시작되지 못하고 있다는 이슈입니다.
logs.dir을 설정했던 로그 파일을 포맷팅해야합니다.
그러나 그냥 같은 명령어를 실행할 경우, 이미 포맷된 폴더라고 에러가 발생해서 저는 폴더를 지우고 재실행했습니다.
the loader is still catching up because we still don’t know the high water mark yet.
두 서버를 스탑하고, 첫번째 서버를 다시 실행할 때 발생한 이슈입니다.
위 로그가 반복되는 현상이 지속되었습니다.
그리고 따라오는 이슈로는
1
[RaftManager id=1] Node 2 disconnected. Connection to node 2 (/외부IP:9095) could not be established. Broker may not be available
서버2와 연결하지 못했다는 오류입니다.
아까 server.properties에 서버2의 컨트롤러 주소를 voters에 추가해서, 서버1이 서버2와 한 클러스터 내에서 연결을 하기 위해 시도했지만, 아직 서버1만 실행중이기 때문에 찾지 못했다는 이슈인데요.
저는 그래서 서버1을 백그라운드로 실행시키고, 서버2도 백그라운드로 실행시켰습니다.
이제 9092,9093,9094,9095 포트가 오픈되었는지 확인해보면,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
root@instance-1:/usr/local/kafka# sudo netstat -antp | grep 9092
tcp6 0 0 :::9092 :::* LISTEN 26269/java
root@instance-1:/usr/local/kafka# sudo netstat -antp | grep 9093
tcp6 0 0 :::9093 :::* LISTEN 26269/java
tcp6 0 0 10.178.0.2:43098 34.22.95.181:9093 ESTABLISHED 26692/java
tcp6 0 0 10.178.0.2:9093 34.22.95.181:43084 ESTABLISHED 26269/java
tcp6 0 0 10.178.0.2:43084 34.22.95.181:9093 ESTABLISHED 26269/java
tcp6 0 0 10.178.0.2:43114 34.22.95.181:9093 ESTABLISHED 26692/java
tcp6 0 0 10.178.0.2:9093 34.22.95.181:43114 ESTABLISHED 26269/java
tcp6 0 0 10.178.0.2:9093 34.22.95.181:43098 ESTABLISHED 26269/java
root@instance-1:/usr/local/kafka# sudo netstat -antp | grep 9094
tcp6 0 0 :::9094 :::* LISTEN 26692/java
root@instance-1:/usr/local/kafka# sudo netstat -antp | grep 9095
tcp6 0 0 :::9095 :::* LISTEN 26692/java
정상적으로 실행중인 것을 확인할 수 있습니다.
저는 스프링 카프카를 사용하기 때문에 추가로 부트 스트랩 서버로 설정하고 연결을 시도해보았습니다.
서버 1

서버 2

정상적으로 파티션을 할당 받았음을 보여줍니다.