
Istio Service Mesh를 사용한 서비스 모니터링 및 부하 분산에 대해서 공유하고자합니다.
현재 제가 구성한 쿠버네티스 아키텍처는 아래와 같이 이루어지고 있습니다.
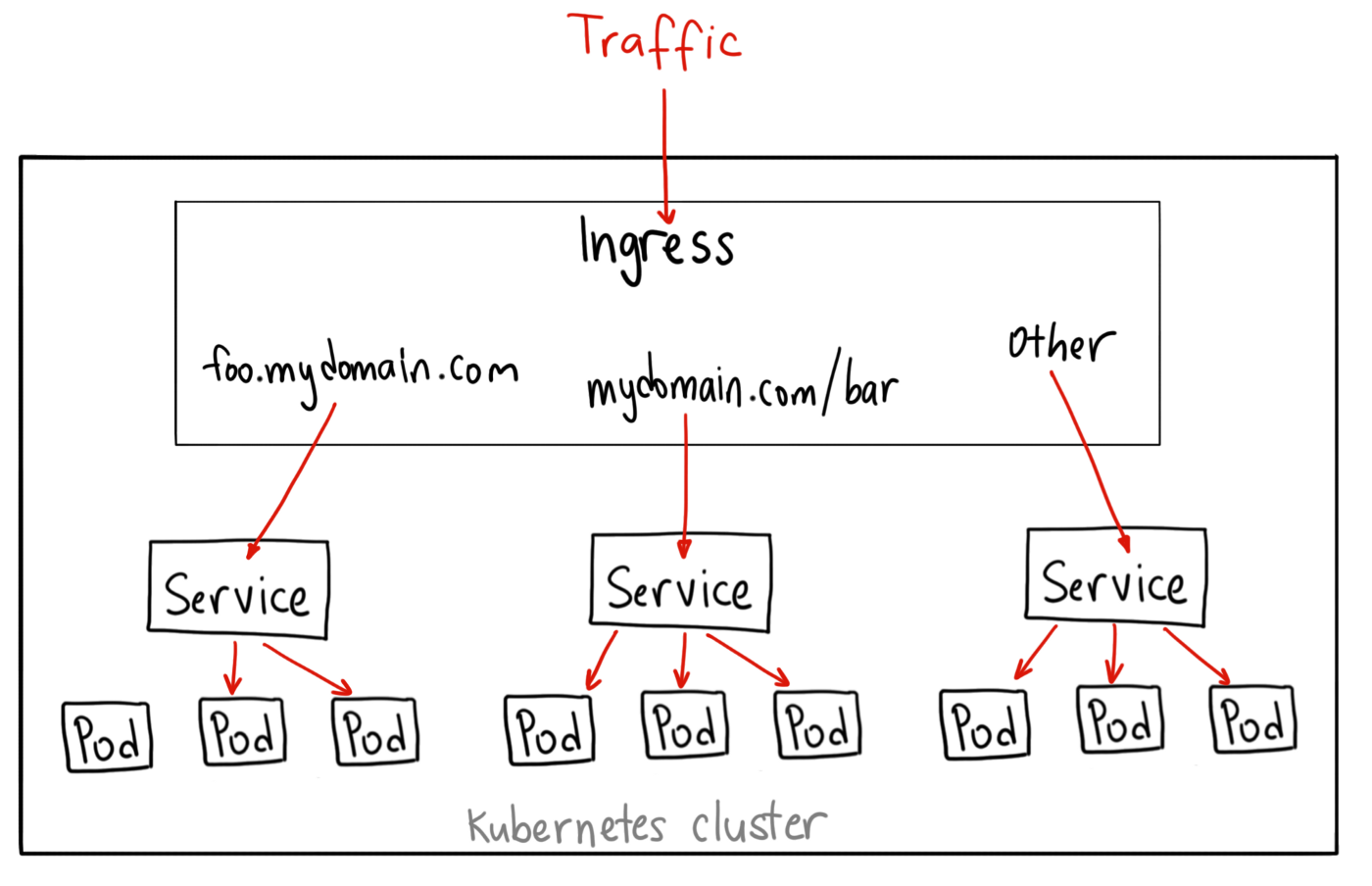
인그레스 - 서비스 - 파드로 되어있기 때문에 인그레스 -> 서비스로 L7 로드밸런싱이 이루어지고
레플리카셋이 복수로 설정되어 있기 때문에, 서비스 -> 파드로 L4 계층의 TCP/IP 기반의 로드밸런싱이 이루어집니다.(서비스의 로드밸런싱 전략은 디폴트인 라운드 로빈입니다.)
AS-IS
쿠버네티스 서비스 오브젝트에는 LoadBalancer 옵션도 존재하는데요.
이는 L4 계층의 부하분산를 해주기 때문에 간단한 환경에서도 충분한 전략이 될 수 있습니다.
그러나 단점으로는 각 디플로이먼트가 서비스에 하나씩 연결되어야하고, SSL/TLS 보안을 적용할 때 서비스마다 적용해야하기 때문에 번거로운 일이 됩니다.
또한 HTTP/HTTPS의 L7 로드 밸런서를 사용하는 것이 더 정교한 부하분산이 가능합니다.
그래서 사용하는 것이 Ingress Controller입니다.
인그레스를 사용하는 경우, URL을 기반으로 하는 트래픽 라우팅이 가능하게 됩니다.
즉, 서비스가 여러개 두어도 인그레스는 하나만 존재해서, 인그레스에서 정의된 규칙으로 목적에 맞는 서비스로 라우팅을 시킬 수 있습니다.
그렇기 때문에 SSL/TLS 보안 옵션도 인그레스에만 적용하면 됩니다.
적용하는 방법은, Let’s Encrypt 인증서로 NGINX SSL 설정하기를 참고해주세요.
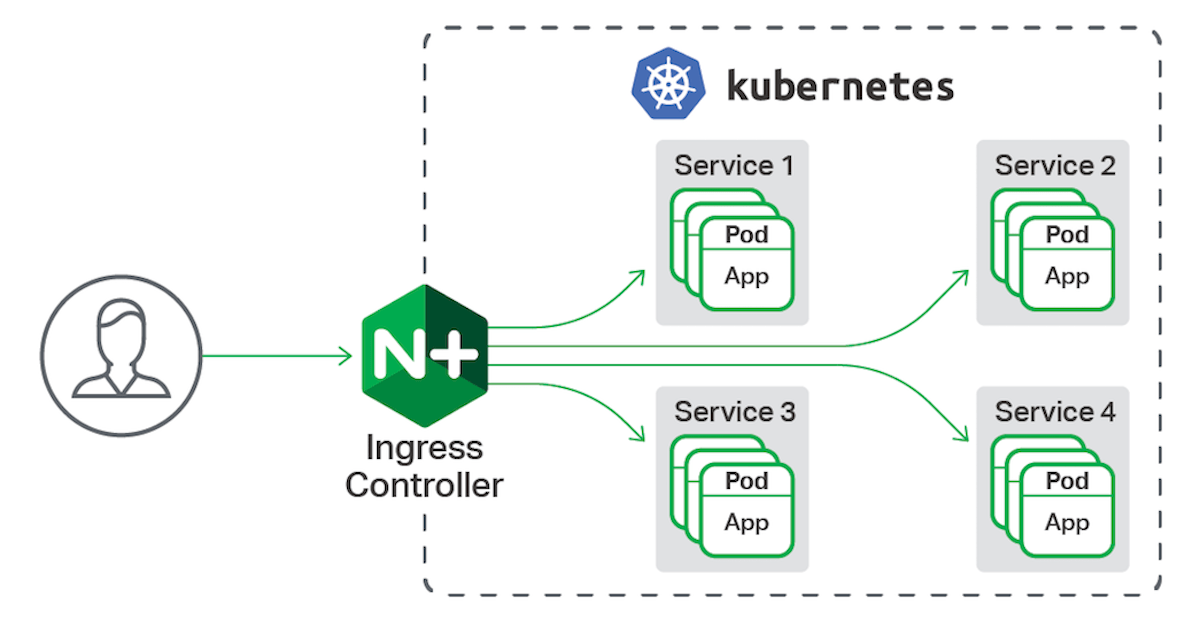
다양한 인그레스 컨트롤러 중, 저는 NginX-Ingress-Controller를 사용했습니다.
즉, Ingress-Controller -> Service -> Pod로 이어지는 구조에서,
Ingress-Controller가 요청을 받아 정의한 Ingress 규칙에 맞게 트래픽을 라우팅하게 됩니다.
인그레스 컨트롤러는 L7계층의 로드밸런싱을 지원하기 때문에 기본적인 트래픽 대응은 이 구조로도 충분하다고 생각합니다.
서비스 계층 모니터링의 필요성
쿠버네티스에서 외부의 요청을 받아들이는 최소한의 계층인 서비스를 모니터링하는 것이 굉장히 중요하다고 생각합니다.
마이크로 서비스 아키텍처에서는 다양한 서비스가 존재하며, 서비스끼리의 의존성이 생길 수 있기 때문에 그만큼 장애 전파의 위험성이 커지게 됩니다.
만약 10개의 서비스에서 1개의 서비스가 장애가 발생하면, 극단적으로 1개의 서비스때문에 10개의 서비스 전체가 장애로 번질 수 있는 위험성이 존재하게 됩니다.
그래서 사용하게 된 것이 Service Mesh 아키텍처입니다.
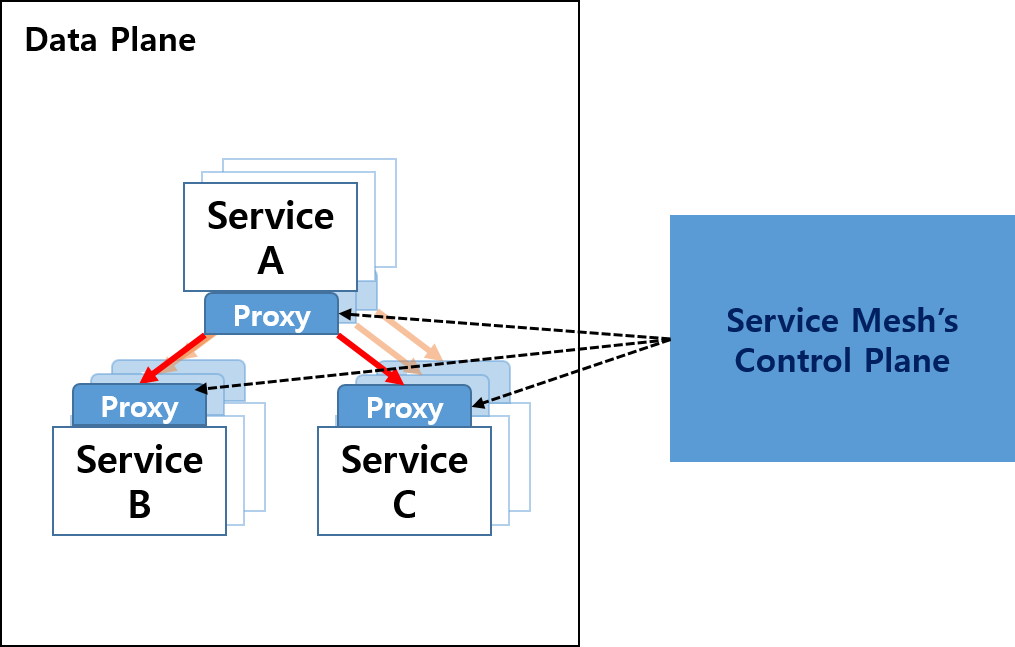
이는 서비스간 호출을 직접 하는 것보다, 앞단에 프록시를 두어 프록시가 다른 서비스의 프록시로 호출하는 등, 서비스에 대한 트래픽을 관리하게 됩니다.
그렇기 때문에 서비스 디스커버리, 서킷 브레이커, 모니터링 등의 다양한 기능을 제공받을 수 있습니다.
그 중 오픈소스이며, 가장 활발히 발전하고 있는 Istio Service Mesh를 사용했습니다.
Istio Service Mesh
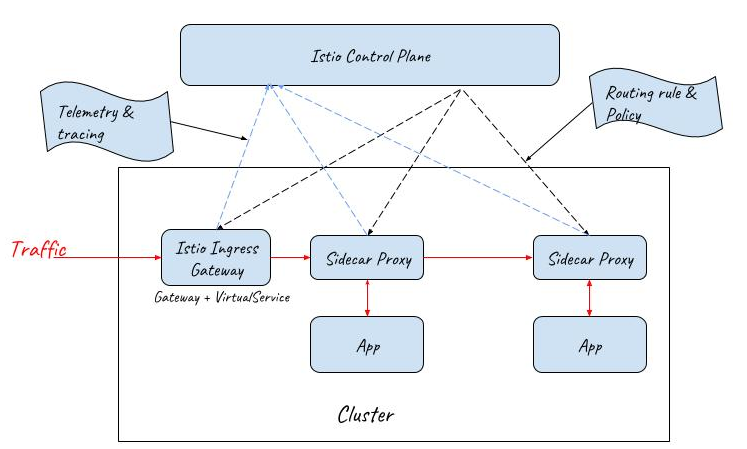
Istio Service Mesh에서는 위에서 언급했던 사이드카 패턴을 Envoy Proxy로 구현하고 있습니다.
위에서 언급했던 프록시를 서비스 앞단에 둔다고 했는데, 이때 Istio측에서 Envoy Proxy를 각 서비스에 배포하게 됩니다. (istio-sidecar-injector가 사용되지만, 이는 주제와 벗어나므로 생략하겠습니다.)
즉 다음과 같이 아키텍처가 구성됩니다.
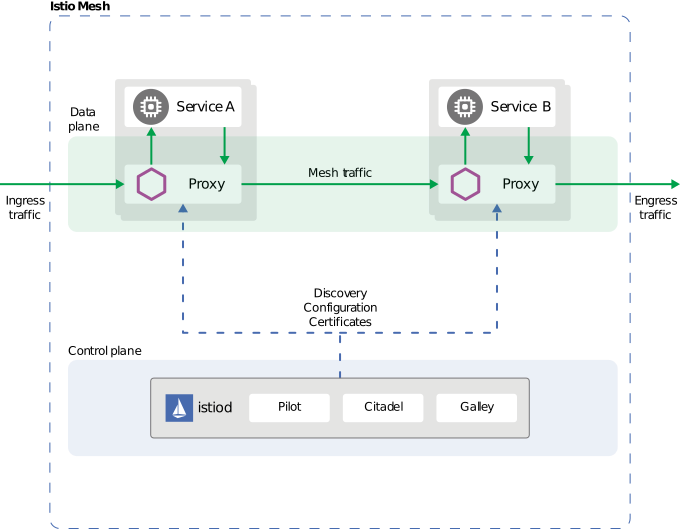
그리고 이를 관리하는 것이
Pliot, Mixer, Citadel로, 각각
- Pliot: 서비스 디스커버리, 배포된 프록시의 생명주기 관리
- Citadel: TLS를 이용한 통신에 대해 Certification 관리
- Mixer: 서비스 모니터링 메트릭 수집(1.5 버전 이후로는 deprecated)
을 담당하고 있습니다.
그리고 Istio는 이를 이용해서
트래픽 분할, 헬스체크, 서킷브레이커 등을 지원합니다.
트래픽 분할
서로 다른 버전의 서비스를 배포하고, 버전별로 트래픽 양을 조절할 수 있습니다.
새로운 버전의 서비스를 배포할 때, 두 버전이 서버에 존재하게 되는 순간이 있는데, 이 때 보내는 트래픽의 양을 조절해서 테스트를 하는 것이 가능합니다.
헬스 체크 및 서비스 디스커버리
파일럿은 서비스가 여러개의 인스턴스로 구성되어 있을 경우 이를 로드밸런싱하며, 이 서비스에 대해서 주기적으로 헬스체크를 하며, 장애가 난 서비스가 있을 경우 서비스에서 제거하게 됩니다.
이것이 서킷 브레이커입니다.
서비스간의 장애 전파를 막고, 호출 안정성을 위해 재시도 횟수를 통제합니다.
보안
Envoy 프록시를 통한 트래픽에 대해서 TLS를 이용해서 암호화합니다.
암호화는 인증서를 사용하는데, 이때 시타델에 있는 인증서를 사용합니다.
모니터링
서비스가 어떤 서비스에 의존하고 있는지와 같은 메트릭을 수집하여 모니터링을 할 수 있습니다.
A 서비스가 B 서비스 호출할 때와 같은 트래픽을 프록시를 통하기 때문입니다.
그리고 수집된 로그는 믹서를 통해 받을 수 있으며, 이는 프로메테우스나 Kiali와 같은 모니터링 툴을 사용해 확인할 수 있습니다.
제 프로젝트의 서비스 트래픽 시퀀스는 아래와 같이 구성되어집니다.
TO-BE
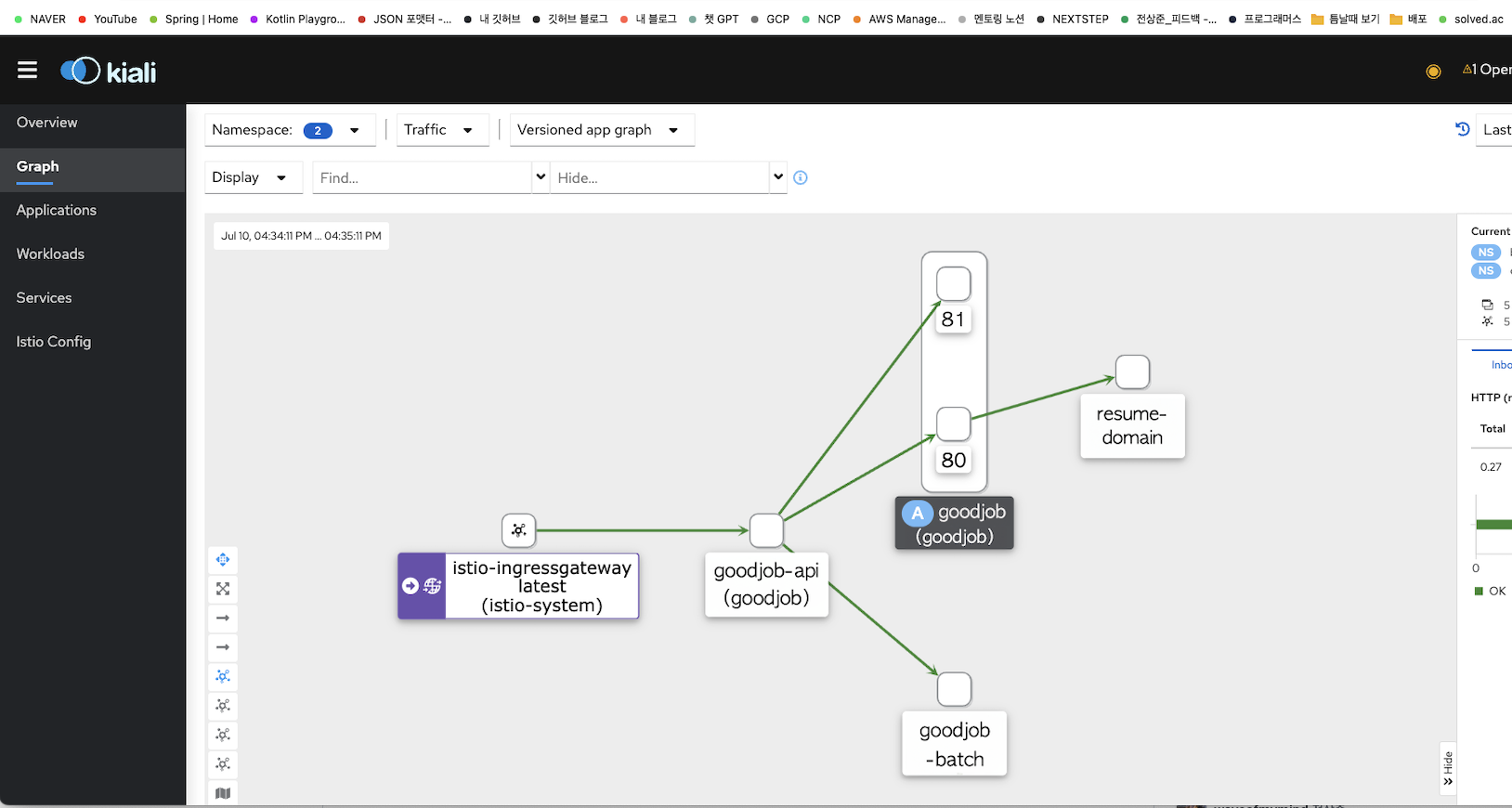
Istio Service Mesh를 사용한 제 쿠버네티스 아키텍처는 아래와 같습니다.
인그레스 컨트롤러가 아닌, 게이트웨이가 앞단에 존재하며,
게이트웨이로부터 트래픽이 VirtualService에 기재된 서비스로 분산되어 각 서비스의 프록시가 이를 받습니다.
추가로, 결국 믹서에 의해 수집된 메트릭은 프로메테우스 -> 그라파나로 모니터링이 가능합니다.
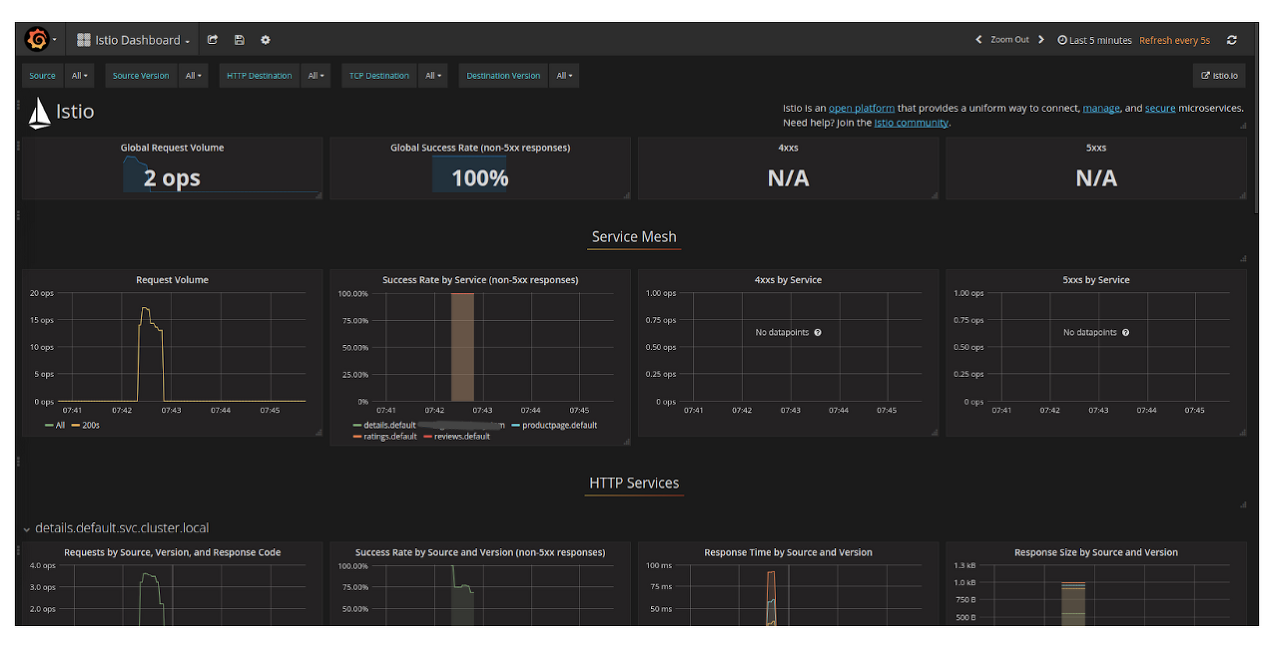
그래서 저는 Istio Service Mesh에 대한 메트릭을 프로메테우스를 통해서 Kiali와 Grafana로 시각화를 시켜서 볼 수 있게 했는데요.
처음에 생각했을 때는 결국 둘다 메트릭을 시각화하는 툴이기 때문에 둘 중 하나만 써도 충분하지 않을까 라는 생각이 들었습니다.
그러나 둘 다 적용해보니 서로 다른 메트릭에대한 접근 방식이 있었습니다.
- Kiali: 서비스 메시의 전반적인 구조를 한눈에 볼 수 있었고, 트래픽이 어떻게 흐르는지, 트래픽에서 어떤 서비스에 대해 문제가 발생했는지에 대한 트래픽의 흐름을 체크할 수 있었습니다.
- 그라파나: 각 서비스의 자세한 메트릭 정보를 시각화해서 볼 수 있었습니다. 흐름보단, 특정 문제가 발생한 서비스의 어떤 점이 문제였는지와 같이 특정 서비스에대한 자세한 정보를 체크할 수 있었습니다.
개인적으로는 Kiali를 통해 모니터링을 하고, 특정 서비스에 문제가 발생했을 경우 그라파나를 통해 해당 서비스의 자세한 정보를 체크하는 것이 제일 효율적일 것이라는 생각이 들었습니다.
이번 프로젝트를 진행하면서, 팀 프로젝트에서 잘 구축된 모니터링 환경은 진행할수록 빛을 발하는 것 같습니다.
배포된 서버에 문제가 발생하면, 실제 스프링부트 서버의 문제가 아닐 경우 인프라쪽 문제가 여럿 있었습니다.
기존에는 실행중인 파드에 로그를 찍어가며 확인하고 파드의 상태를 체크하는 일이 대다수였지만, 앞으로는 kiali와 그라파나를 통해 효율적으로 모니터링을 할 수 있게 되었습니다.