
이전에 굿잡 프로젝트에서 게시글 목록 조회에 캐시를 적용했습니다.
게시글 목록은 새로운 게시글이 추가됨에 따라 캐시 데이터와 DB 데이터와의 정합성을 어느정도 보장해야 했기 떄문에
TTL을 5초정도로 짧게 가져가서 완전한 정합성을 포기하는 대신 가용성을 챙긴 트레이드 오프였습니다.
그러나 문제는 부하 테스트 중 발견됬는데요.
5초가 지난 후 캐시가 만료되고, 여러 요청이 캐시 미스가 발생하여 동시에 여러번의 select 쿼리와, 캐시에 중복으로 쓰여지는 현상이 있었습니다.
이러한 문제를 어떻게 해결했는지 공유하고자합니다.
Cache Stampede는 왜 발생할까?
캐시를 사용하게 되면 지연로딩 방식으로 전략을 세우며, 이는 캐시에 요청 데이터가 있으면 캐시에 있는 데이터를 사용하고, 없을 경우에 데이터 스토어에 데이터를 요청하게 됩니다.
그리고 해당 데이터를 캐시에 쓰고, 다음 요청에서는 캐시에 있는 데이터를 사용할 수 있게 됩니다.
그러나 자주 변경되어야 하는 데이터의 경우 보통 TTL을 설정하게 되는데요.
AWS에서도 캐싱 전략으로 데이터를 최신 상태로 유지함과 동시에 복잡성을 줄이기 위해 TTL을 추가하는 것을 권장하고 있습니다.
그러나 TTL을 설정하는 것은 트래픽이 많아질 경우 문제점이 됩니다.
만약 많은 요청이 캐시 힛으로 데이터를 응답중에, 캐시 만료기간이 되면 어떻게 될까요?
만료 시간이 도달함에 따라 캐시에서 데이터가 날아가기 때문에 데이터 스토어로의 많은 요청이 몰리게 됩니다.
이러한 현상을 Cache Stampede라고도 합니다.
그리고 지연로딩 방식에 따라서 해당 데이터 스토어의 많은 요청들이 캐시에 써지게 되고,
Dubplicate read와 Duplicate write가 발생하게 되는 것입니다.
즉 아래와 같이 그림으로 나타내어집니다.
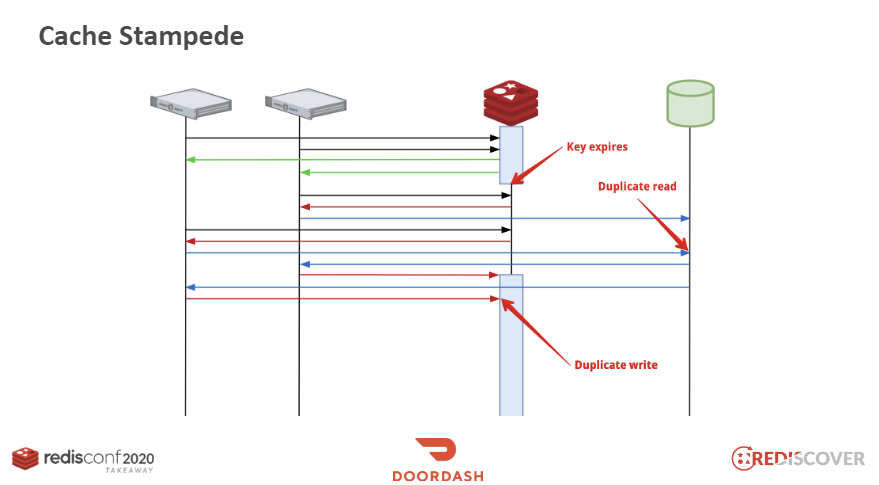
요청에 대해서 캐시에 데이터가 없을 경우 서버는 DB에서 데이터를 가져와 레디스에 저장하게 되는데,
키가 만료되는 시점에는 동시에 많은 서버에서 이 키를 참조하는 시점이 겹치게 됩니다.
배치 작업을 통한 캐시 데이터 갱신
가장 먼저 떠올릴 수 있는 해결 방법은 주기적으로 캐시 데이터를 갱신하는 방법입니다.
배치 작업을 통해서 캐시 데이터를 갱신하게 되면 문제를 해결할 수 있다고 판단했습니다.
즉, TTL을 설정하여 만료 시간을 주어 캐시 데이터를 삭제시키는 것은 데이터가 자주 갱신되어야하기 때문인데,
TTL을 설정하지 않고 배치 작업을 통해 캐시 데이터를 갱신시키는 방법입니다.
장점으로는, 만료 시간을 정하지 않기 때문에 만료가 되지 않는다.라는 것을 보장할 수 있습니다.
단점으로는, 배치를 사용하기 위해 추가적인 리소스가 필요하며, 결국 배치 작업을 통해 갱신할 키를 직접 선정해야하므로 추후 유지보수에 있어서 번거로움이 있을 수 있습니다.
캐시 미스에서 Lock을 사용하기
캐시 미스가 발생할 경우 DB에 가는 요청에 대해서 Lock을 활용해서 중복 조회, 수정을 방지하는 전략입니다.
이는 Cache Stampede를 발생하는 것을 막을 수 있지만, 이 때문에 다른 요청들이 대기하게 되어 병목 현상을 초래합니다.
Probabilistic Early Expiration
알고리즘을 사용해서 TTL 만료 전에 데이터를 갱신시키는 방법입니다.
핫 키에 대해서 TTL 만료를 연장시킴으로써 연장이 지속적으로 이루어지기 때문에 Cache Stampede 발생을 막을 수 있습니다.
또한 확률에 따라 갱신 확률이 높아지기 때문에 핫 키를 관리할 필요가 없습니다.
그래서 저는 위 PER 알고리즘을 적용하기로 했습니다.
PER 알고리즘 적용하기
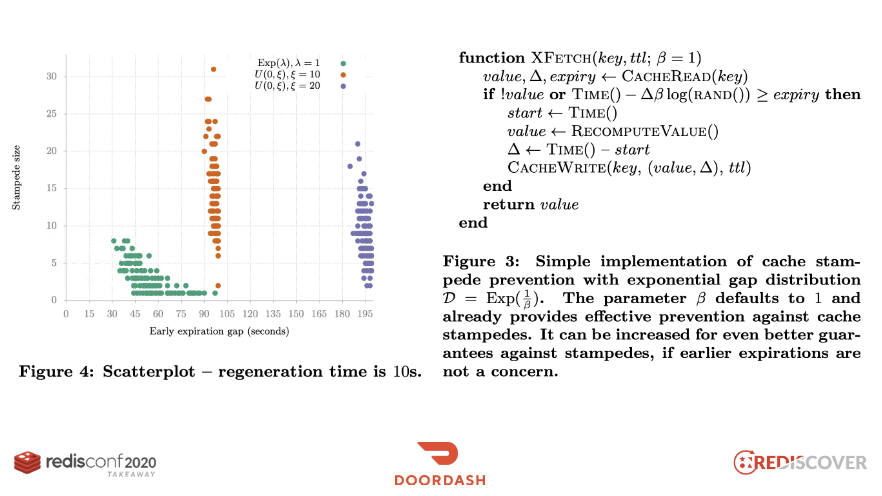
알고리즘을 적용했을 때의 로직은 다음과 같아집니다.
key를 사용해서 캐시에서 값을 얻어옵니다.- 캐시 미스가 발생했다면(값이 존재하지 않을 경우) RecomputeValue()를 호출합니다.(값을 조회)
- 조회한 값을 캐시에 쓰고, ttl 시간으로 설정합니다.
- 값을 응답으로 반환합니다.
즉, TTL까지 남은 시간이 -∆βlog(rand())보다 작거나 같을 경우 해당 키를 갱신시켜야합니다.
∆(Recompute Time Interval)
캐시를 다시 쓰는 일련의 과정에 대한 시간을 나타냅니다.
이 동작이 오래 걸릴수록 Cache Stampede가 발생하는 것이 문제를 더 크게 발생시킵니다.
이 값에 비례하게 구성하여 TTL 만료시간이 비교적 많이 남더라도, RTI가 클 경우에는 갱신시켜야합니다.
β(갱신 상수)
default = 1로, 높을수록 갱신이 잘 발생합니다.
-log(rand())
rand()는 [0,1)의 범위의 균일 분포를 가진 난수를 생성하며,
평균이 1인 지수 분포를 따르게 되기 떄문에, 요청 사이의 시간을 모델링할 때 사용됩니다.
즉, 각 캐시 히트를 독립적인 사건으로 판단하기 위해서 지수 분포를 사용하는 것입니다.
캐시가 만료되기 전에 얼마나 빨리 새로운 값을 계산할지를 결정하는데 사용됩니다.
지수분포와 그에 대한 스케일링을 통해 캐시 항목의 재계산 시간을 고려합니다.
이러한 값들을 사용함으로써
−δ×β×log(randomValue)≥remainTtl식은 다음과 같은 의미를 가집니다.
- 델타값이 큰 경우: remainTtl이 존재하는 동안 갱신이 이루어져야하기 때문에(시급) 갱신을 시킵니다.
- 반대로 델타값이 낮은 경우(계산 속도가 빠른 경우)나 아직 갱신하지 않아도 될 경우(remainTtl이 높은 경우)에는 재계산하지 않습니다.
-(음의 부호)가 붙은 이유
이 부분이 궁금했는데요.
기본적으로 randomValue는 0과 1 사이의 값을 가지게 되고, log는 0에서 음의 무한대의 값을 가집니다.
즉, randomValue가 1에 가까울 수록 음의 무한대에 가까워지기 때문에 이를 양의 값으로 바꿔주기 위해 사용됩니다.
이렇게 하면 결과값은 대부분 작은 양의 값을 가지며, 가끔 큰 양의 값을 가지게 되는 것입니다.
이를 통해 남은 TTL과 재계산이 필요한 시간 간격을 비교해서, 재계산이 필요한 시간 간격이 남은 TTL보다 큰 경우(즉, 데이터를 가져오는데 더 많은 시간을 소요할 경우)에 재계산을 수행하도록 합니다.
적용 로직
단순히 캐시만 적용했었던 로직은 아래와 같습니다.
1
2
3
4
5
6
7
@Cacheable(value = "articles", key = "#page.pageNumber")
override fun getArticleList(page: Pageable): FindArticleListResponse {
return articleRepository.findArticleList(page).stream().map { article ->
val user = userService.findUser(article.userId)
FindArticleResponse.from(article, user.email)
}.collect(Collectors.toList()).let { FindArticleListResponse.of(it) }
}
@Cacheable을 사용했기 때문에, CacheConfig에는 value가 articles일 경우 TTL을 5초로 설정했습니다.
키값은 단순히 pageNumber만 주었습니다.
그리고 다음으로는 Probabilistic Early Expiration 알고리즘을 적용했을 때의 로직입니다.
1
2
3
4
5
6
7
8
9
override fun getArticleList(page: Pageable): FindArticleListResponse {
val key = getReadAllArticleCacheKey(page)
return articleCacheService.perGet(key, { args ->
articleRepository.findArticleList(page).stream().map { article ->
val user = userService.findUser(article.userId)
FindArticleResponse.from(article, user.email)
}.collect(Collectors.toList()).let { FindArticleListResponse.of(it) }
}, Collections.emptyList(), TTL) as FindArticleListResponse
}
우선 articleCacheService가 추가되었는데요.
기존에 @Cacheable을 사용하면 키에 대한 TTL값을 가져올 수 없기 때문에 어노테이션이 아닌, 직접적으로 캐시에 쓰고 읽는 기능을 구현해야합니다.
저는 Redis를 사용하기 때문에 RedisTemplate을 사용했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
fun perGet(
originKey: String,
recomputeValue: Function<List<Any>, Any>,
args: List<Any>,
ttl: Int
): Any? {
val key = hashtags(originKey)
val result = redisTemplate.execute(cacheGetRedisScript, listOf(key, getDeltaKey(key))) as List<*>
val valueList = result[0] as List<*>
val data = valueList[0]
val delta = valueList[1] as Long
val remainExpiryTime = result[1] as Long
if (data == null || delta == null || remainExpiryTime == null ||
-delta * BETA * kotlin.math.ln(randomDoubleGenerator.nextDouble()) >= remainExpiryTime) {
val start = System.currentTimeMillis()
val computedData = recomputeValue.apply(args)
val computationTime = System.currentTimeMillis() - start
setKeyAndDeltaWithPipeline(ttl, key, computedData, computationTime)
return computedData
}
return data
}
주요 로직을 설명하면,
- originKey로 부터 실제 키를 가져옵니다.
- execute()를 통해 luaScript에 정의한 명령어를 통해 값을 가져옵니다.
- 데이터가 없거나, 델타값이 없거나, 남은 만료시간이 없거나, 남은 시간이
-∆βlog(rand())보다 크거나 같을 경우 캐시의 값을 갱신시킵니다. - 그리고 해당 값을 반환합니다.
아까 이론적으로 설명했던 과정과 동일합니다.
LuaScript를 사용하는 이유
데이터 조회 및 해당 데이터의 TTL을 원자적으로 수행하기 위햐서입니다. 또한, mget으로 조회 후 pttl로 확인하기 때문에 RTT를 줄일 수 있습니다.
루아 스크립팅을 이용함으로써 조회 및 TTL 확인 사이에 어떤 명령어도 끼어들 수 없기 때문에 데이터를 조회할 때의 TTL에 대해 순서에 따른 동시성 이슈를 발생하지 않기 위해서입니다.
검증
이제 다시 부하테스트를 통해 캐시 히트 확률이 얼마나 되는지 확인해보겠습니다.
우선 테스트 환경은 다음과 같습니다.
- AWS EC2 Ubuntu 22.04 LTS t2.micro (1v CPU, RAM 1GB)
- AWS Elasticashe Redis cache.t2.micro (싱글)
- AWS RDS(MySQL) db.t3.micro
모두 프리티어로 사용할 수 있는 환경입니다.
그리고 테스트 조건은 다음과 같습니다.
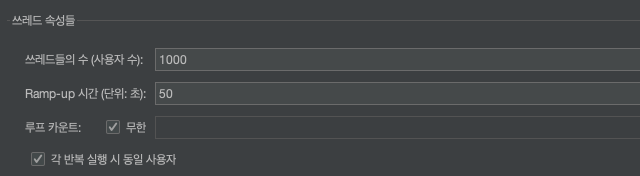
그리고 각 요청들에 대해서 page를 랜덤으로 요청시키기 위해 사전처리기를 작성합니다.
저는 평균 50, 표준편차 2의 정규분포에서 랜덤한 값을 생성시켰습니다.
그리고 테스트는 두 테스트 모두 동일하게 200k의 요청을 기준으로 했습니다.
1. PER 알고리즘을 적용하지 않았을 때
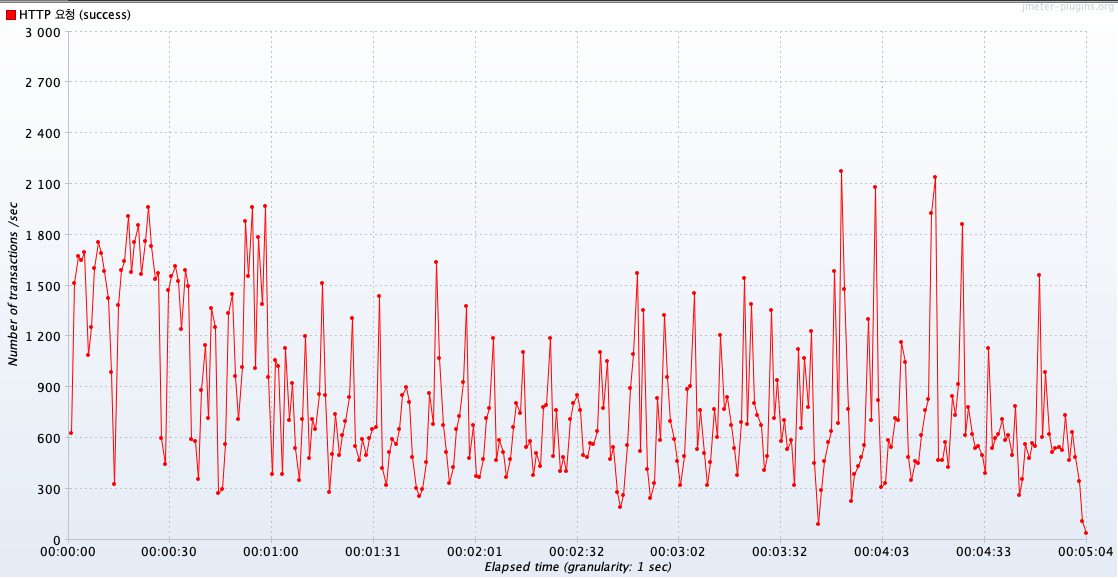
평균 TPS는 약 822 정도가 나왔습니다.
2. 알고리즘 적용 후
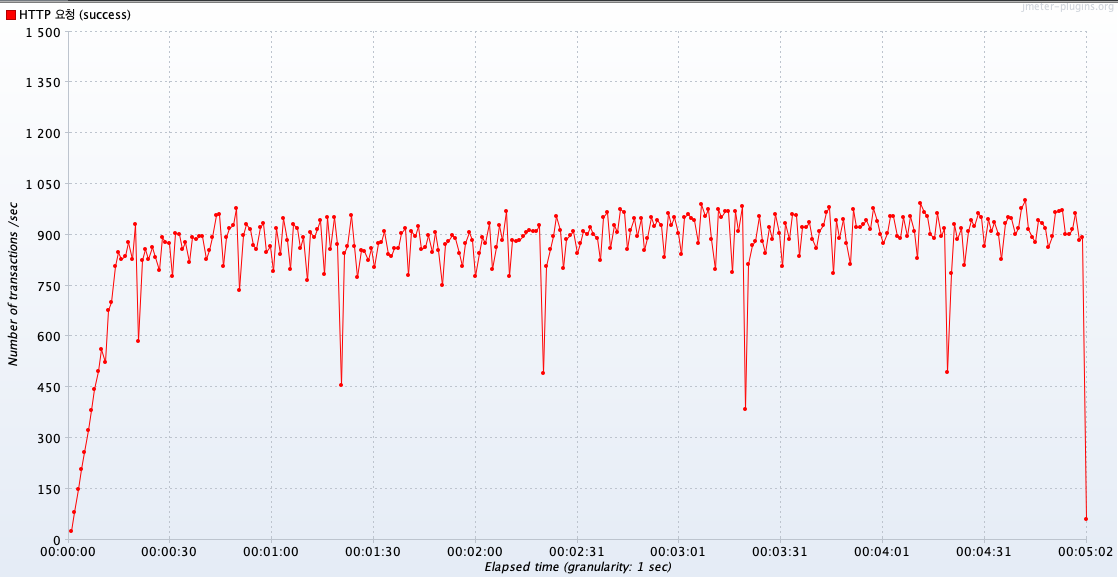
평균 TPS는 약 860 정도가 나왔습니다.
적용 전과 후의 평균 TPS는 비슷하지만, 그래프 양상이 다릅니다.
첫번째 그래프는 만료되고나서 캐시 미스가 발생하기 때문에 Cache Stampede가 발생하고,
그렇기 때문에 그래프의 낙폭이 현저하게 높습니다.
두번째 그래프는 반대로 그래프가 안정적으로 보여집니다.
즉, 캐시 데이터가 만료 전에 갱신되기때문에 캐시 미스가 줄었기 떄문에, 평균적으로 안정적인 트래픽을 받아낼 수 있게 됬습니다.
이제 Redis와 RDS 각 지표를 통해 결과를 확인해보겠습니다.
PER 적용 후와 적용 전 테스트의 시간대는 각각 16:06 ~ 16:13, 16:23 ~ 16:29입니다.
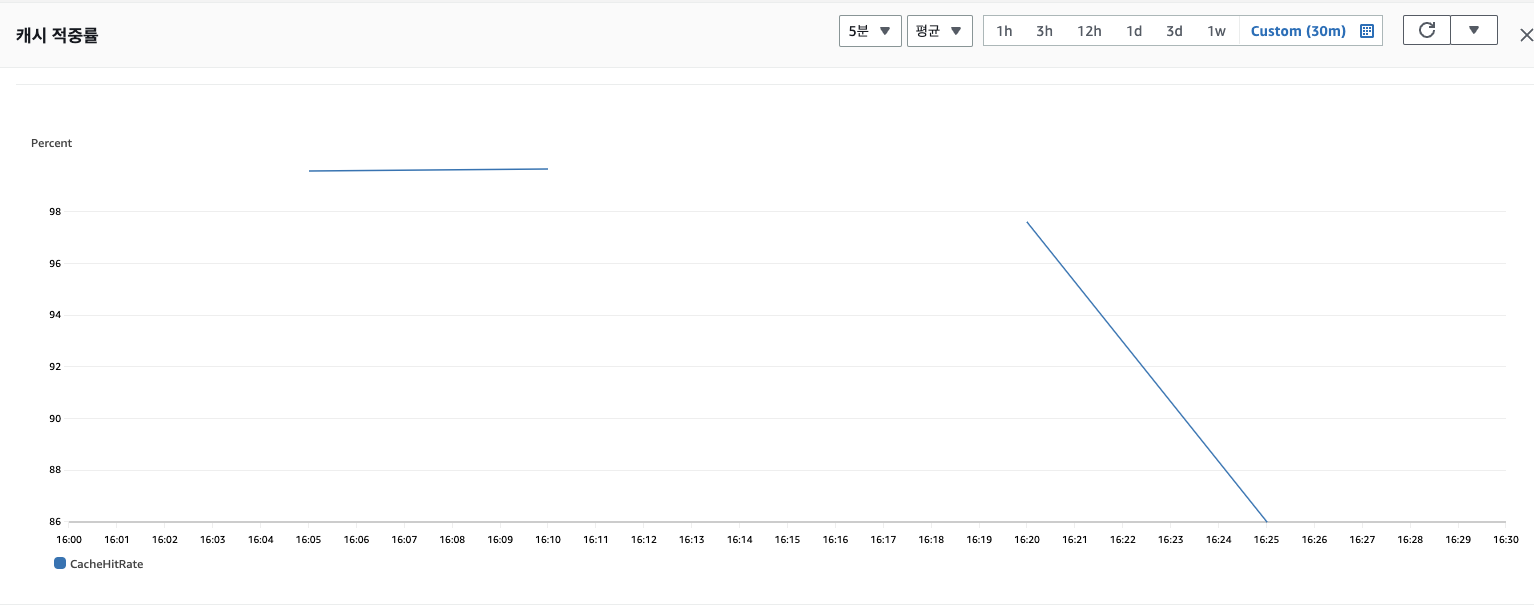
알고리즘 적용 전에는 평균 89%, 적용 후에는 평균 99.6%정도로 캐시 히트율이 약 10퍼센트 증가했습니다.
그리고 다음은 캐시 미스율입니다.
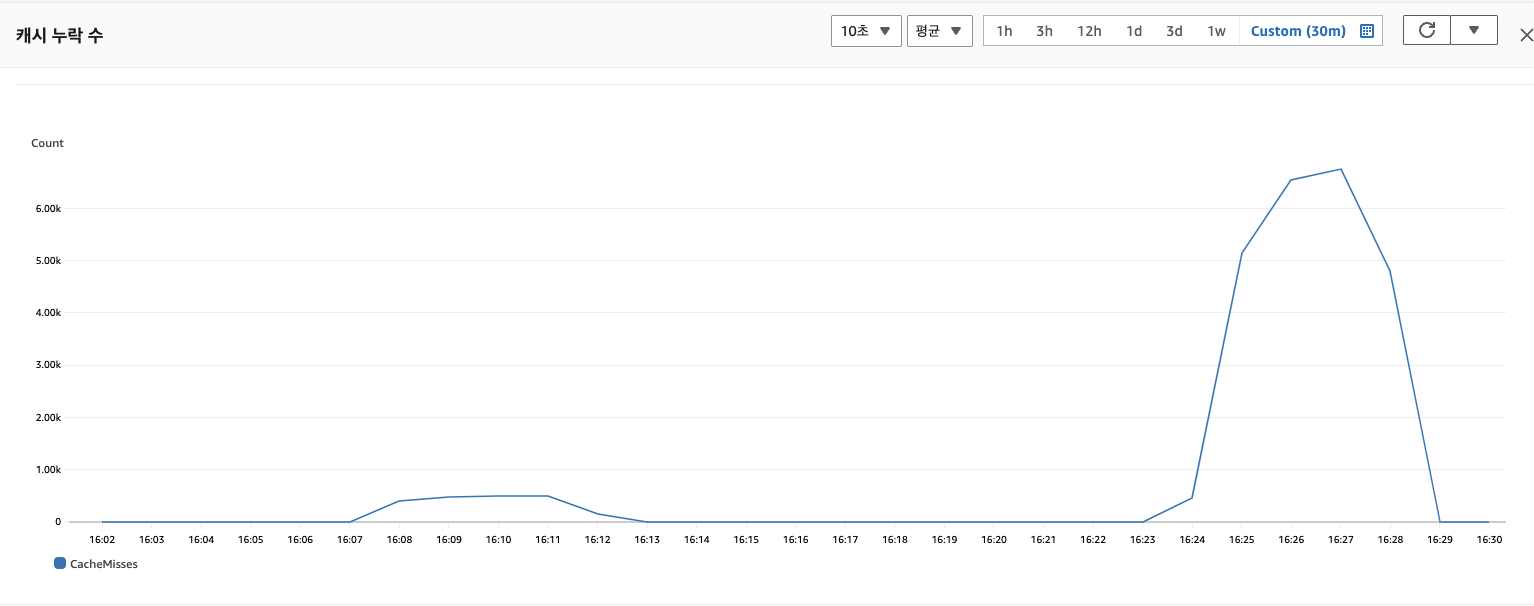
알고리즘 적용 전에는 캐시 미스율 평균 5000번, 적용 후에는 490번 정도가 발생했습니다.
10분의 1로 줄어든 것을 확인할 수 있습니다.
그리고 마지막으로 RDS CPU 사용률을 체크해보겠습니다.
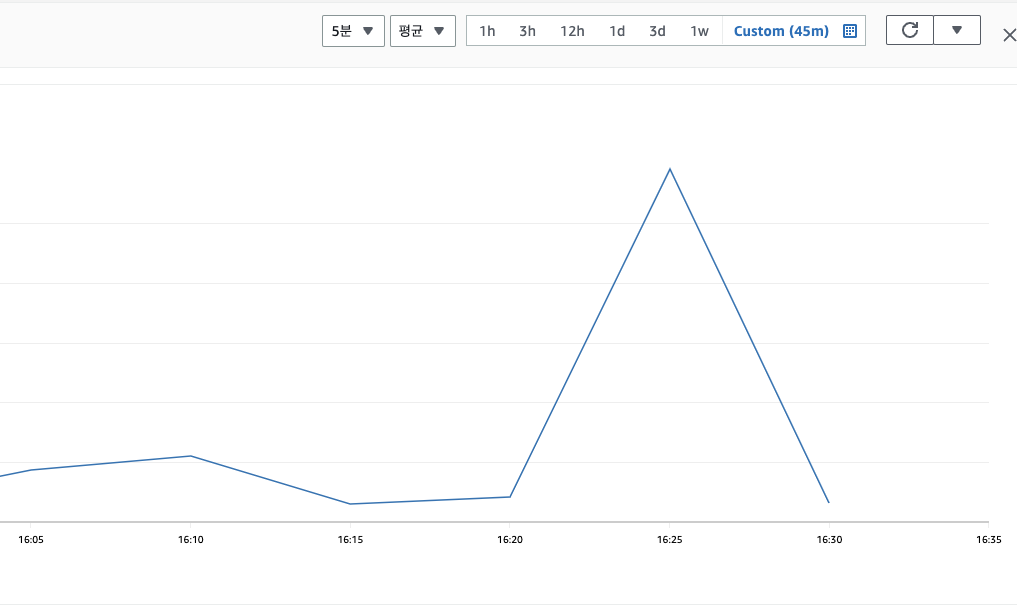
알고리즘 적용 전에는 평균 66%, 적용 후에는 15%정도로 확연히 줄어들었습니다.
이전의 설명대로, Cache Stampede가 더 자주 발생한 알고리즘 적용 전 테스트가 높은 RDS CPU 사용률을 보여줍니다.
테스트를 위해서 간단한 로직에 대해서 테스트를 진행했기 때문에 적용 후에 99.6%의 히트율을 보여주었지만, 더 복잡한 로직에 대해서는 점차 테스트를 할 예정입니다.