
굿잡 프로젝트의 커뮤니티 서비스에서
게시글 목록 조회시 캐시를 도입하면서 겪었던 트레이드 오프에 대해 공유하는 글입니다.
AS-IS
저희 굿잡 프로젝트는 생성 AI 서비스를 제공하는 것 외에도 커뮤니티 서비스, 최신 채용 공고 서비스, 실시간 채팅 기반의 멘토링 서비스를 제공하고 있습니다.
커뮤니티 서비스는 저희 서비스를 이용하는 사용자들이 가장 오랜시간 사용할 것이라고 판단했는데요.
그 이유는 다음과 같습니다.
- 채용 공고 서비스에 대한 내용을 커뮤니티 서비스에서 다른 사용자와 의견을 나눌 것이다.
- 멘토링 서비스는 같은 회원이 멘토이기 때문에 커뮤니티 서비스에서 알고 신청할 가능성이 있다.
- 생성 AI 서비스의 결과에 대해 질의 응답 및 의견을 나눌 것이다.
라는 점에서 였습니다.
그래서 저는 커뮤니티 서비스를 중점적으로 부하테스트를 진행하며 TPS를 더 높일 수 있는 방법에 대해서 고려하게 되었습니다.
캐싱
저는 이전까지 게시글과 관련에서 캐시를 사용했을 때 이점을 누리는 것은 조회수나 좋아요 같은 주기적으로 update가 이루어지는 로직일 것이라고 생각했습니다.
정합성이 보장되어야 하는 데이터를 캐시에 저장하면 사용자가 조회했을 때 실제 데이터와 다를 수 있기 때문입니다.
만약 사용자가 게시글을 작성하여 DB에 저장이 되었는데 캐시에 반영이 안되어 사용자가 게시글을 확인할 수 없기 때문입니다.
Write Through 방식으로 우선 캐시에 데이터를 쓰고 DB에 인라인으로 쓰기를 하는 방법도 있지만,
Disk I/O에 저장하는 속도와 캐시에 저장하는 속도의 차이가 크기 때문에 캐시를 사용하는 장점을 누릴 수 없을 것이라고 판단했습니다.
그래서 저는 게시글 목록에 대해서 캐싱을 적용했을 때의 장점과 단점에 대해서 정리해보았고, 크게 두가지가 있었습니다.
- 게시글 목록을 캐시에 저장하여 우선적으로 체킹하면 데이터 정합성이 Disk I/O와 맞지 않게된다.
- TPS가 증가할 것이다.
즉, 정합성과 TPS 사이에서의 트레이드 오프에 대해서 고민해보게 되었습니다.
저는 그래서 완전한 정합성을 포기하고 TTL을 짧게 가져가면 되지 않을까라는 생각을 했는데요.
목록 조회이기 때문에 사용자는 목록 조회 -> 상세 게시글 진입 -> 게시글 수정 or 삭제, 댓글 작성의 매커니즘으로 움직일 것으로 판단했으며, 상세 조회시 정확한 글만 보여주면 될 것이라고 판단했습니다.
그래서 저는 TTL을 5초로 짧게 가져가는 방법을 택했습니다.
우선 간단한 게시글 조회 로직을 구현하여 JMeter를 통해 검증해보겠습니다.
사용할 로직은 아래와 같습니다.
1
2
3
4
5
6
7
8
@Override
public FindArticleListResponse getArticleList(Pageable page) {
return FindArticleListResponse.of(articleRepository.findArticleList(page).stream()
.map(article -> {
FindUserResponse response = userService.findUser(article.getUserId());
return FindArticleResponse.from(article, response.email());
}).toList());
}
게시글을 조회하고, 게시글 작성자도 조회해서 최종적으로 DTO로 변환하고 응답하는 간단한 로직입니다.
위 로직을 JMeter를 통해 테스트 해보겠습니다.
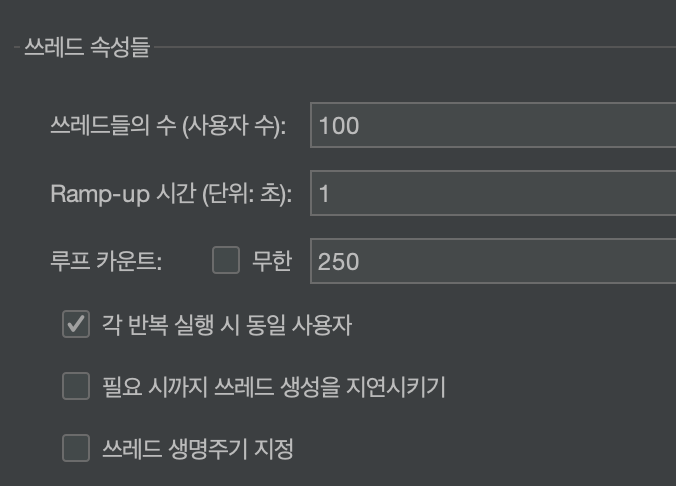
위와 같은 조건으로 부하테스트를 진행했습니다.
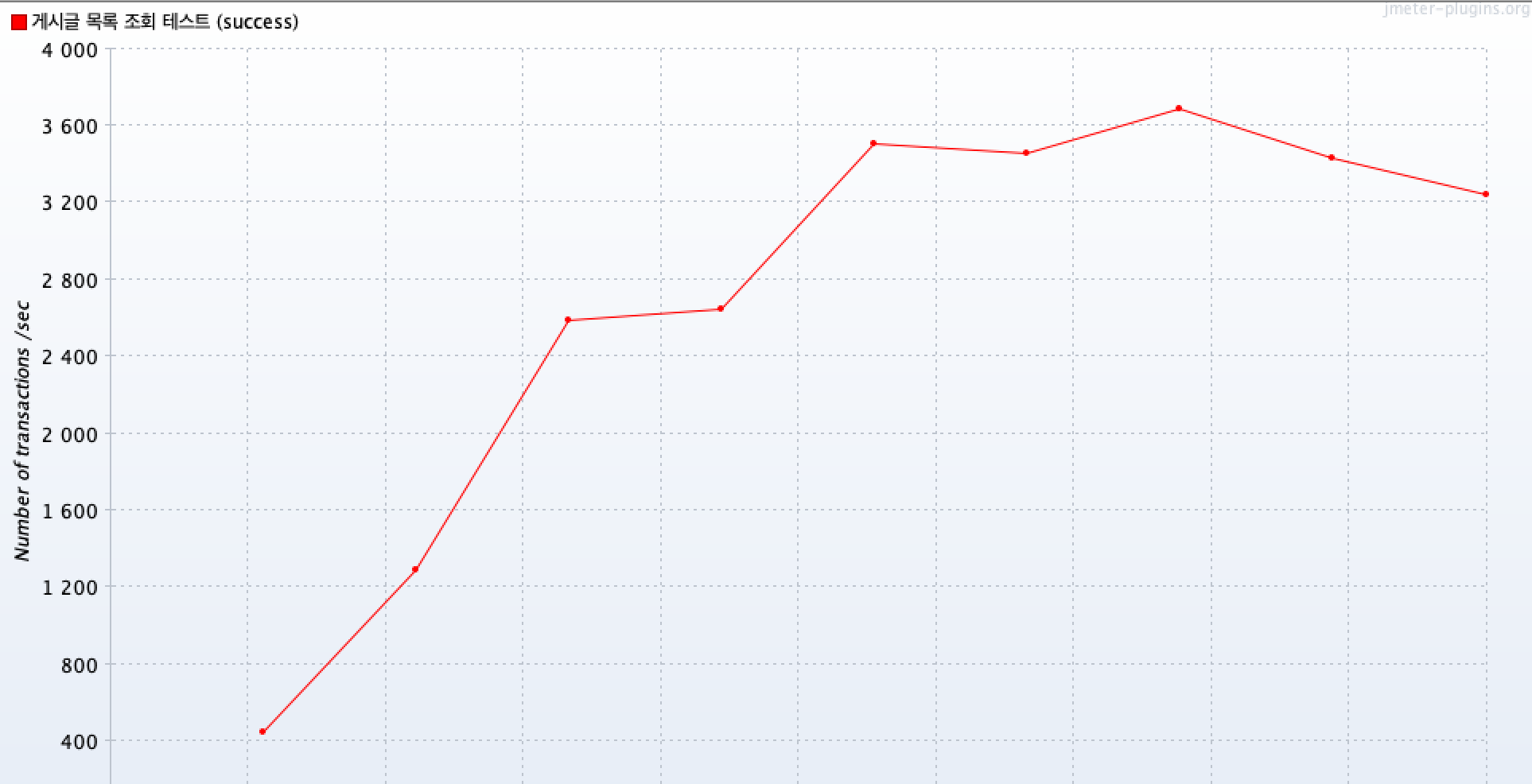
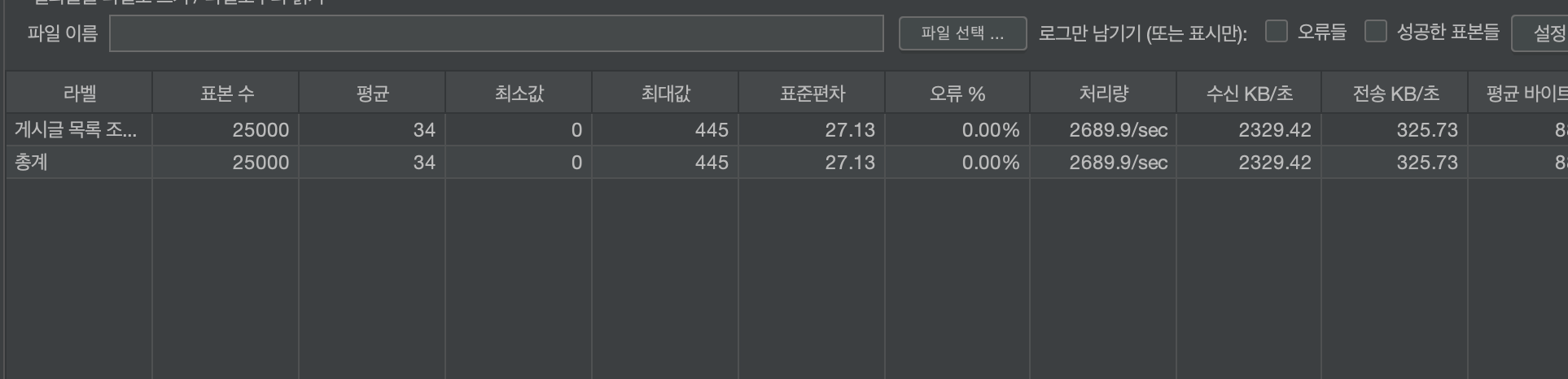
그 결과 평균 TPS가 2072정도가 나왔네요.
이제 캐시를 적용해보겠습니다.
스프링 부트에서는 간단하게 @Cacheable로 사용할 수 있으며,
저는 로컬 캐시와 분산 캐시 중 분산 캐시인 Redis를 사용하게 되었습니다.
저희 굿잡 프로젝트는 쿠버네티스 환경에서 복수의 파드로 로드밸런싱이 되어 있으며,
백업 서버 또한 존재하기 때문에 여러 서버 인스턴스가 Redis 서버를 바라볼 필요가 있었기 떄문입니다.
1
2
3
4
5
6
7
8
9
@Override
@Cacheable(value = "articleList", key = "#pageable.pageNumber")
public FindArticleListResponse getArticleList(Pageable page) {
return FindArticleListResponse.of(articleRepository.findArticleList(page).stream()
.map(article -> {
FindUserResponse response = userService.findUser(article.getUserId());
return FindArticleResponse.from(article, response.email());
}).toList());
}
캐시 매니저는 생략하고, @Cacheable을 적용한 코드만 보여드리겠습니다.
캐시 매니저에서는 articleList 밸류인 경우 TTL을 5초로 설정하였습니다.
이제 다시 테스트를 진행해보겠습니다.
테스트 조건은 위 테스트와 동일합니다.
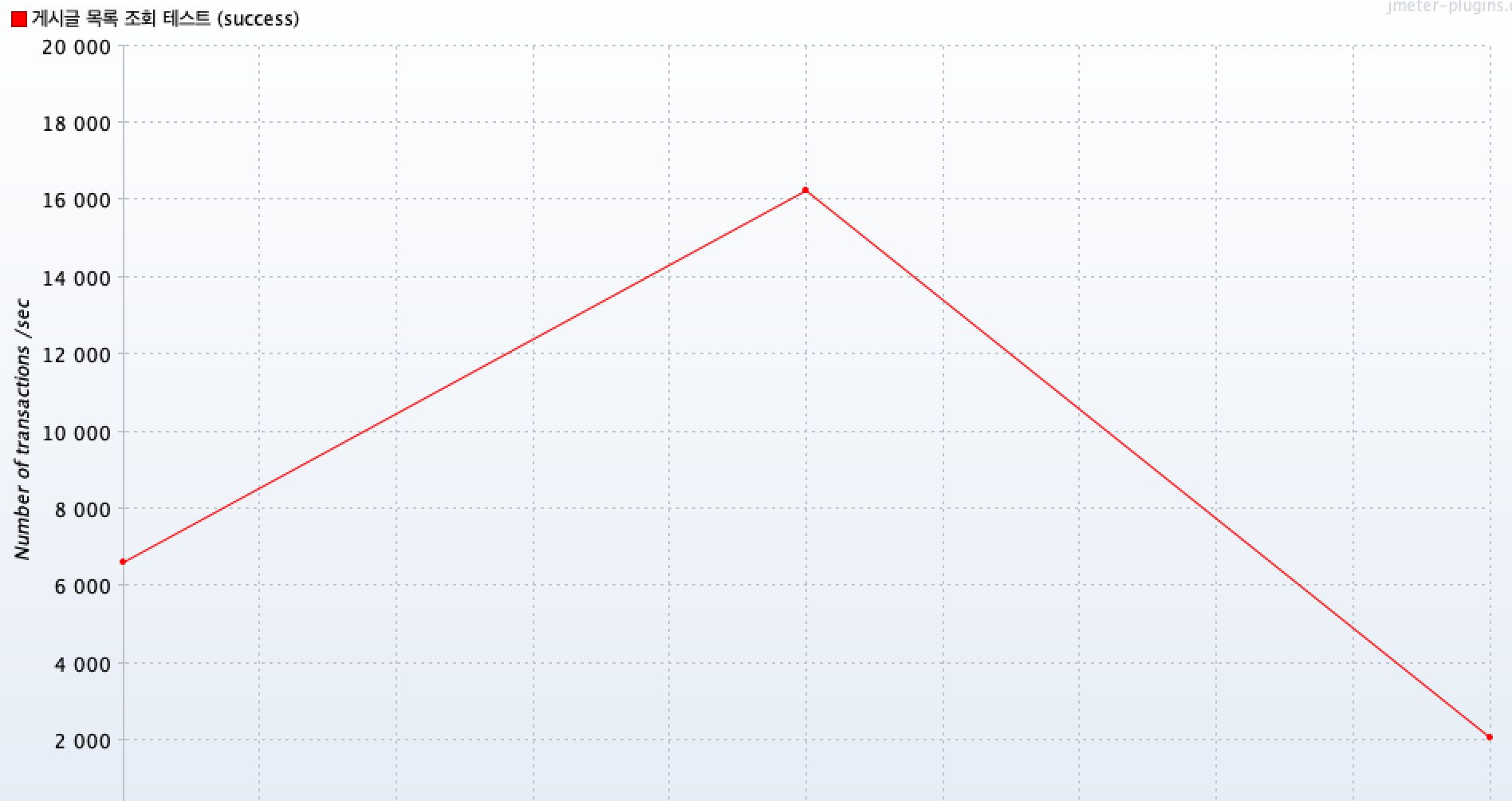
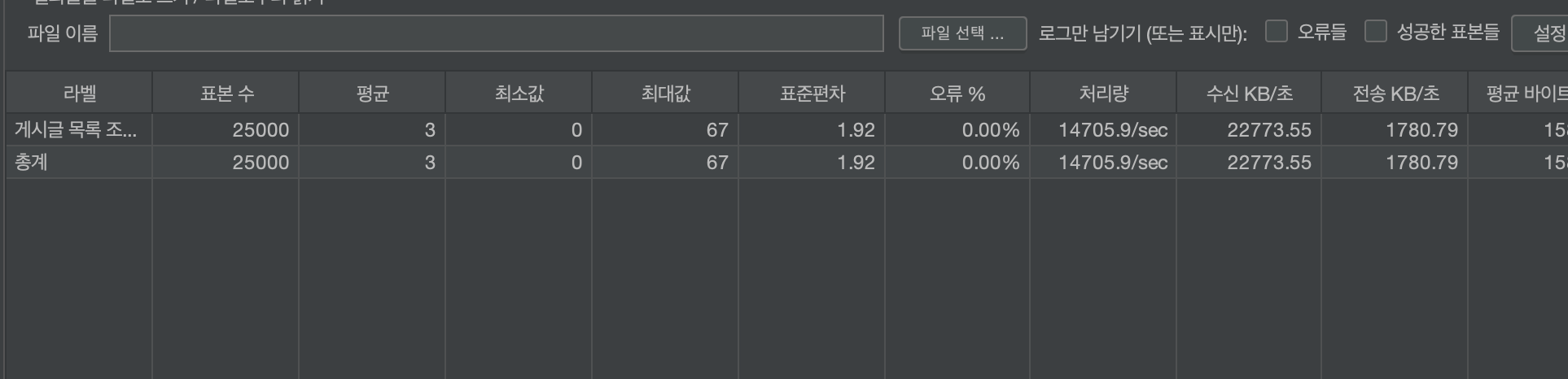
캐시 적용 후 평균 TPS가 약 12474정도가 나왔습니다.
첫 조회 이후 5초동안은 직접 DB를 거치지 않고 캐시에 있는 데이터만을 조회하게 됩니다.
평균 TPS가 약 6배정도 향상되는 것을 확인할 수 있습니다.
TO-BE
이제 간단한 프로젝트에서 성능 향상을 검증했으니, 굿잡 프로젝트에 적용해보겠습니다.
캐시 매니저 설정은 동일하게 게시글 목록 조회시 TTL을 5초로 두었습니다.
굿잡 프로젝트의 캐시 적용 전 함수는 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
@Transactional(readOnly = true)
public Page<ArticleResponseDto> findByCategory(int page, int id, int sortCode, String category, String query) {
Pageable pageable = PageRequest.of(page, 12);
List<Article> articles = articleRepository.findQslBySortCode(id, sortCode, category, query);
List<ArticleResponseDto> articleResponseDtos = articles
.stream()
.map(articleMapper::toDto)
.collect(Collectors.toList());
return convertToPage(articleResponseDtos, pageable);
}
이제 JMeter를 사용해서 TPS를 측정해보겠습니다. 테스트 환경은 이전과 동일합니다.
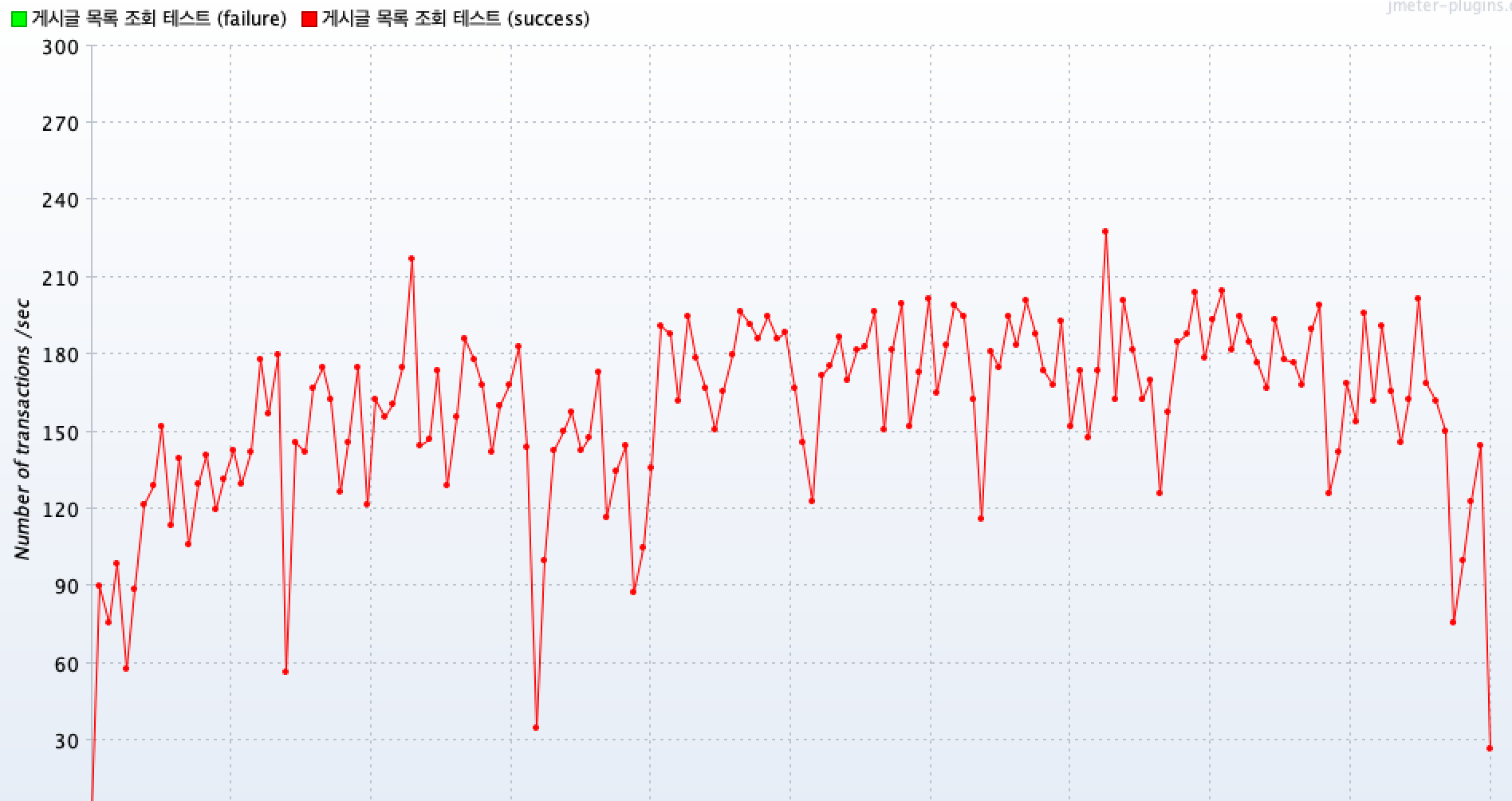
캐시 적용 전 평균 TPS는 약 140정도가 나왔네요.
이제 캐시를 적용해보겠습니다.
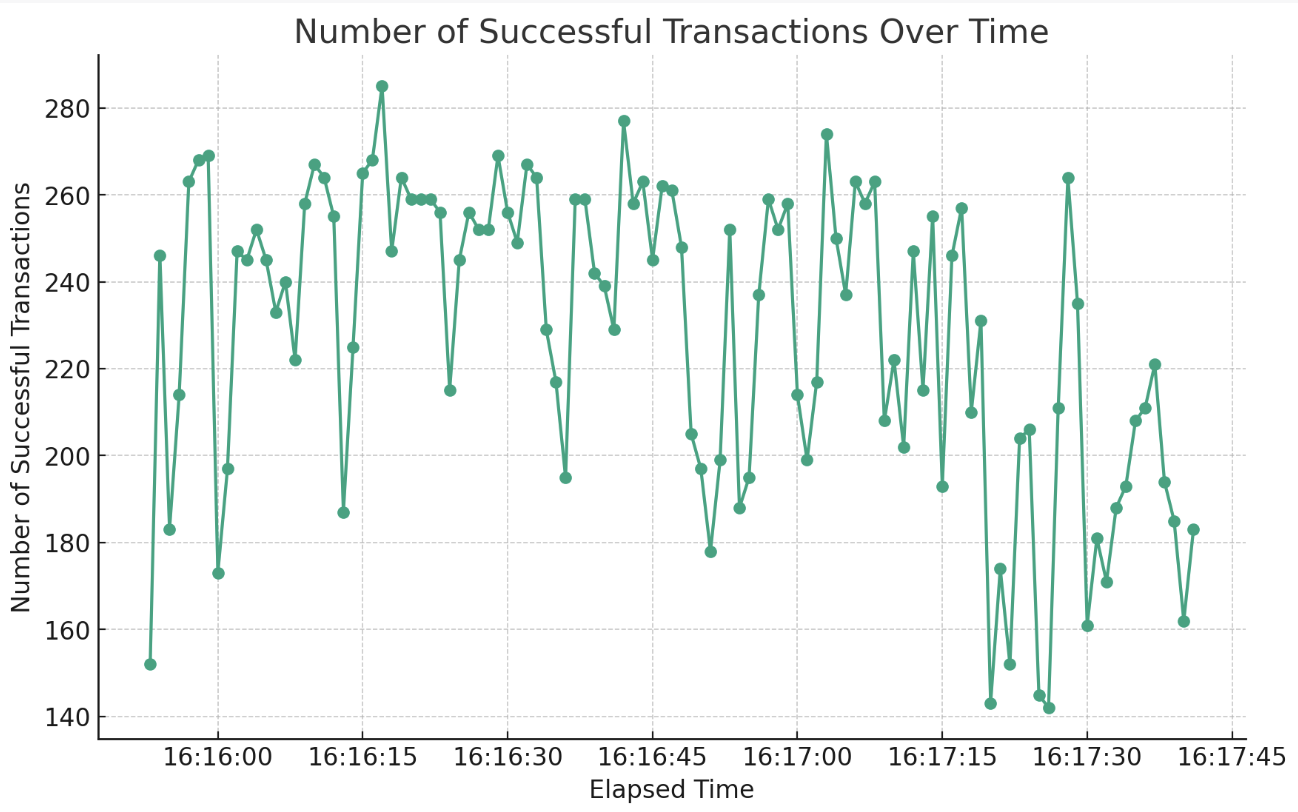
캐시 적용 후에는 약 230으로
약 45프로정도 증가한 것을 보여줍니다.
이는 모두 로컬 환경이지만, 운영 서버의 경우 클라우드 환경에서의 서버 사양에 따라 달라질 수 있을 것 같습니다.
회고
위 과정을 겪으며, 저는 게시글 목록 조회시에 캐시를 도입하기로 했습니다.
커뮤니티 서비스 특성상 게시글 목록 조회보단 상세 조회시의 정합성이 더 중요하다고 생각했고,
저희 서비스에서 커뮤니티 서비스가 가장 이용자가 많을 것이라고 판단하여 데이터 정합성을 잠깐이나마 포기하는 대신 TPS를 높이는 것이 더 효율적일 것이라고 판단했습니다.
또한 진행하면서 한가지 개선점을 발견했는데요.
Select 쿼리가 발생하면서 생기는 DB 부하에 대해서도 개선할 수 있었습니다.